
AI 부트캠프 8주 : Section 2 Project

AI 부트캠프 8주차 : Section 2 Project
부트캠프를 시작한지 벌써 두 달 가까이 지나갔다.
그리고 시작한 두 번째 프로젝트.
두 번째 프로젝트는 자유주제였다.
주제선정, 데이터 선정 부터 분석, 발표까지 ‘알아서’ 해야 한다.
주간회고
더 공부가 필요한 부분
- 머신러닝을 프로젝트에 적용할 때 프로젝트에 알맞은 데이터, 모델, 해석, 시각화가 다른 것 같다.
다양한 프로젝트를 경험하고 싶다.
5F 회고
-
사실(Fact)
머신러닝 프로젝트의 기획부터 발표까지의 과정을 얕게나마 경험하였다. 제출된 모든 동료들의 발표영상을 시청하였다. -
느낌(Feeling)
정말 다양한 머신러닝의 주제가 있고, 창의적이고 새로운 전처리, 모델링, 분석 방법이 있음이 놀라웠다. -
교훈(Finding)
나는 학습하며 배운 것만 반복 연습했는데, 그래서 창의력이 떨어지는 결과물이 나온것 같다. -
향후 행동(Future action)
창의력은 성장의 원동력이 되기 때문에 조금 더 새로움을 시도해 보자. -
피드백(Feedback)
발표 PPT의 가독성을 높이면 좋겠다는 피드백을 받았다.
중요특성 갯수를 왜 4개로 선정했는지에 대한 질문을 받았다.
완성영상 보기
프로젝트 계획 및 과정
1. 프로젝트 계획
| 날짜 | 내용 |
|---|---|
| 1/31 (화)~2/2 (목) | • 프로젝트 준비✅ • 주제 선정 • 데이터 탐색 |
| 2/3 (금) | • 프로젝트 START🚀 • 관련 아티클 검색 |
| 2/4 (토) | • 데이터 전처리 |
| 2/5 (일) | • Feature Engineering • 탐색적 데이터분석 |
| 2/6 (월) | • 모델링 • 하이퍼파라미터 튜닝 • 머신러닝 모델해석 |
| 2/7 (화) | • PPT 슬라이드 작성 • 스크립트 작성 |
| 2/8 (수) | • 영상촬영 • 최종 제출🚩 |
2. 주제선정
- 상황 가정
- 인공지능 데이터를 기반으로 건축을 하는 ‘AI건설’은 직원이 3,000명 정도 되는 대기업이다.
- 회사의 직원들은 ‘현장 건설 직원’, ‘건축 자제 대형마트 직원’, ‘컴퓨터 데이터분석 직원’ 3분야의 직원들이 있다.
- 3가지 산업분야의 직원들이 섞여있기 때문에 똑같은 포상제도에 불만을 가지고, 핵심인력이 회사에서 퇴사하는 문제가 생겼다.
- 3가지 산업분야의 직원들에게 효과적인 포상제도를 마련하여 한정된 자원안에서 효과적으로 직원이탈을 줄이고자 한다.
- 이를 위하여 머신러닝을 통하여 각 분야의 직원들에게 효과적인 포상제도는 무엇인지 분석하고 제안하고자 한다.
3. 주제관련 아티클 조사
- 포상의 의미
- 포상은 다양한 수요를 반영하고 칭찬과 격려, 모범사례의 확대라는 긍정적 의미를 지니지만, 포상이 남발되거나 대상자가 제대로 선정되지 않을 경우 포상의 권위와 신뢰성이 떨어지는 문제가 발생함
포상은 '보상'과는 다르다.- ‘보상’은 행위에 대한 금전적 보상의 의미가 강하지만, 포상은 조직의 목표 달성을 위한 인센티브의 의미가 강하다.
- 직원들에게 효과적으로 포상 주는 핵심방법 3가지 포인트
- 포상을 할 때 중요한 3가지
- 비 현금성 포상
- 비균일성 포상
- 비제도성 포상
- 효과적인 포상이 되려면
- 실용보다 더 큰 명예로움을 포상
- 실물보다 더 큰 감사를 포상
- 실무자의 업무가 아닌 경영자의 리더십으로 포상
- 포상을 할 때 중요한 3가지
- 소속감 다지는 인센티브 여행, 가장 효과적인 직원 포상 방법
4. 데이터 선정
- 한국노동패널 데이터 원자료
- 한국노동패널조사(Korean Labor and Income Panel Study: KLIPS)는 우리나라에서 가장 오래된 패널조사 가운데 하나
- 도시지역에 거주하는 가구와 가구원을 대표하는 패널표본 구성원을 대상으로 1년에 1회씩 조사를 실시하여 1998년 1차 조사를 시작으로 2021년 24차 조사까지 완료된 신뢰성있는 데이터이기 때문에 본 연구에 적합함
- 각 산업분야 근로자들의
근로관련 특성과 직무만족도, 생활만족도와 같은 본 연구를 위한 특성이 존재하여 본 연구에 적합함
5. 데이터 전처리
- 데이터 준비
- 데이터를 불러와 객체로 저장
# 노동패널 조사 차수 리스트
wave_list = [
'01', '02', '03', '04', '05', '06', '07', '08', '09', '10', \
'11', '12', '13', '14', '15', '16', '17', '18', '19', '20', \
'21', '22', '23', '24'
]
# Read Data
for i, val in enumerate(wave_list):
globals()[f'klips_{val}_raw'] = pd.read_stata(path_data + f'klips{val}p.dta')
- 전체 column : 16,169 개
- 전체 case : 348,029 개
- ‘복리후생 관련 문항’이 4차년도부터 조사되었기 때문에 4차년도 이후만 사용
- 특성 선택
- 기본 특성, 가구 정보, 기업형태 및 규모관련 문항, 근로계약 관련 문항, 근로시간 관련 문항, 임금 및 소득 관련 문항, 노조관련 문항, 복리후생 관련 문항, 요인별 직무만족도, 기술 적합도 및 향후 일자리 전망, 직업훈련 관련 문항, 자격증 관련 문항, 혼인관련 문항, 만족도 관련 문항
- 케이스 선택
- 8차 한국표준산업분류
- 컴퓨터 직군 : 정보처리 및 기타 컴퓨터 운영 관련업
- 721, 722, 723, 724, 729
- 판매업 직군 : 소매업
- 521, 522, 523, 524, 525, 526
- 건설업 직군 : 종합 건설업
- 451, 452
- 특성공학
- 타겟 : 생활만족
- 교육수준 : 초등학교 이하, 중학교, 고등학교, 전문대, 대학교, 석박사
- 거주지역 : 수도권(서울,인천,경기도), 비수도권
- 소득 : 평균 월 급여액
- 재직기간 : 취업일부터 현재까지의 경과 날짜
- object 데이터타입을 category 데이터타입으로 변경
- category 데이터타입으로 순서 지정
- 메모리 사용량 감소
변환 전 메모리 사용량 : 6,392,838
변환 후 메모리 사용량 : 1,775,009
6. 탐색적 데이터분석
- 탐색적 데이터분석
- 타겟 : ‘만족한다’라고 응답한 비율 37%
- 약하게 타겟이 불균형 함
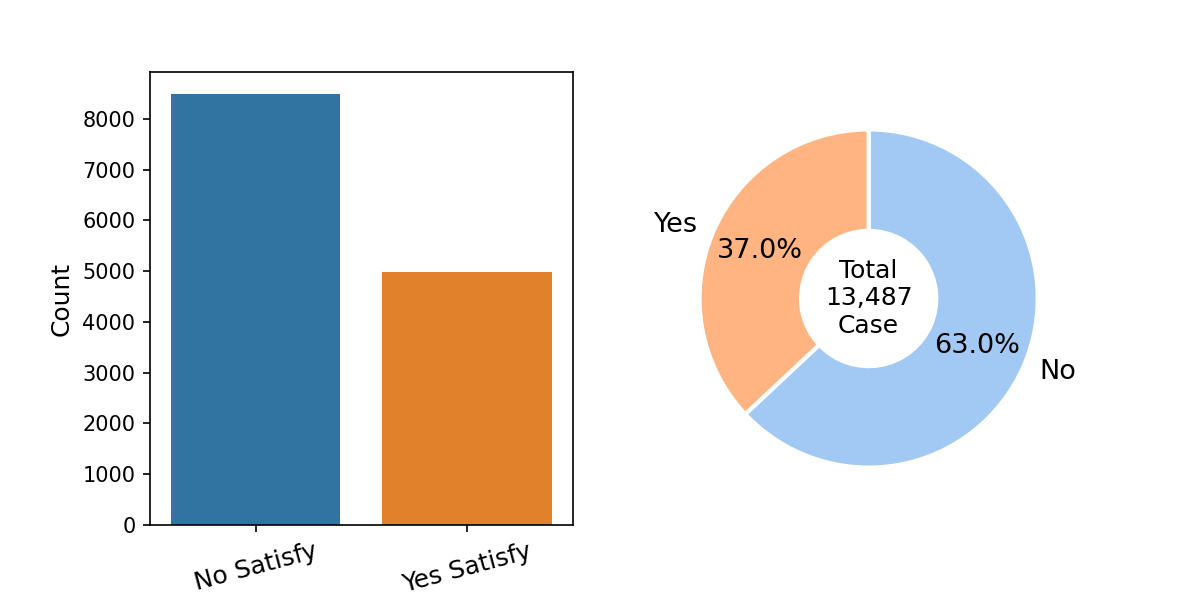
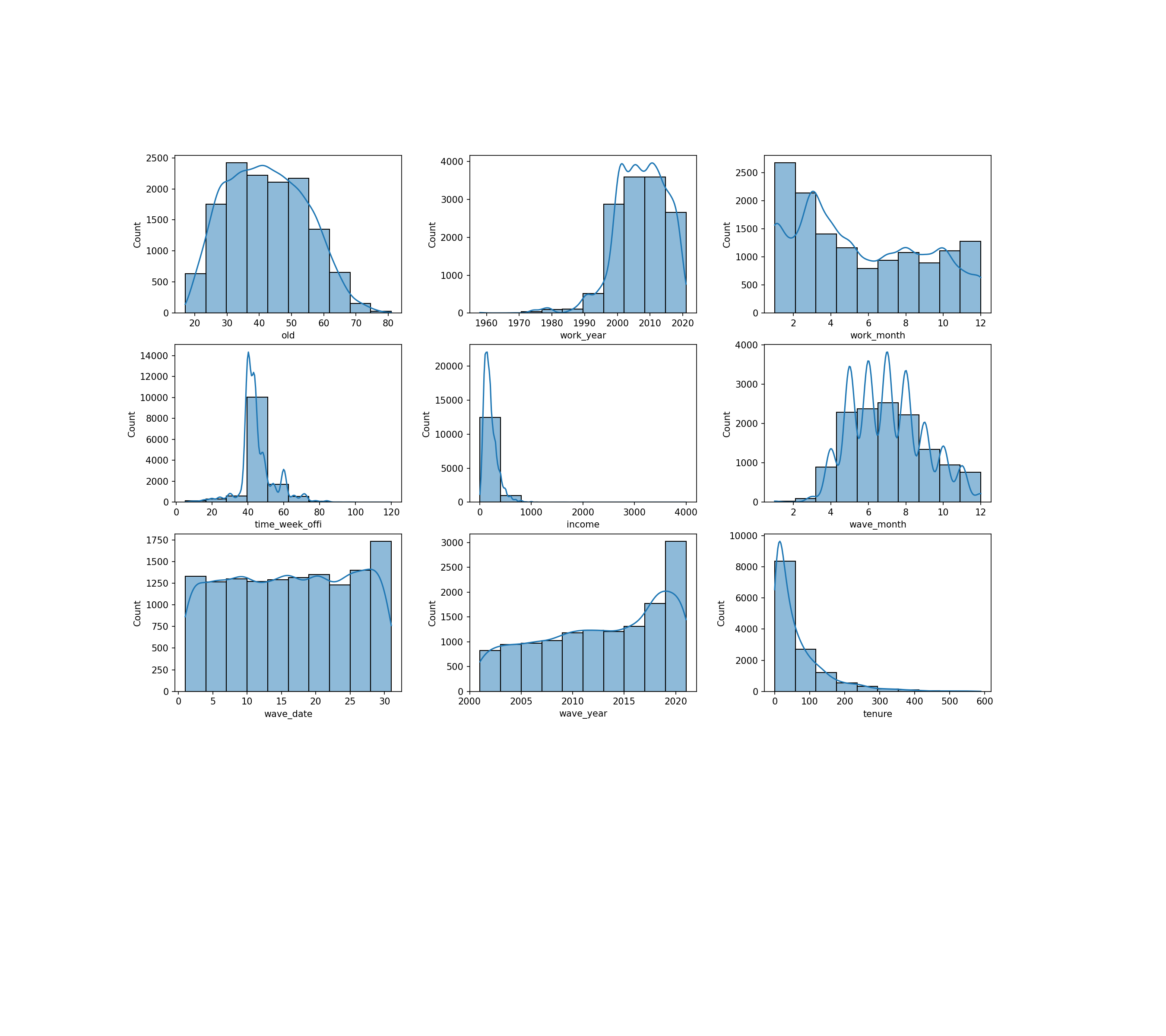
- 숫자형 변수
- 데이터 분포
- 편향된 분포가 보이지만 분류문제에서는 데이터의 분포가 성능에 크게 영향을 미치지
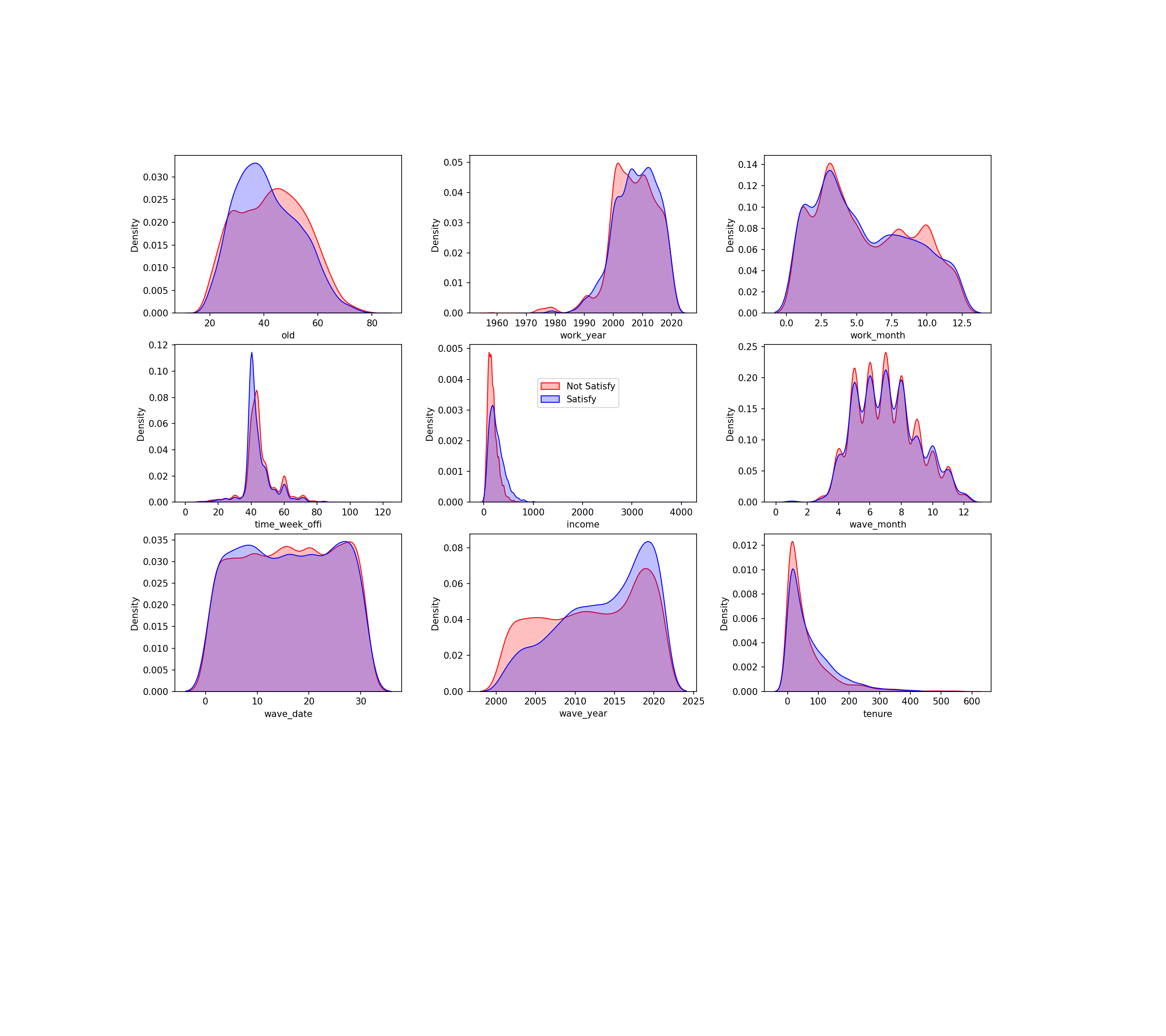
- 타겟에 따른 데이터 분포1
- 이상치가 일부 보이지만 우려할 수준은 아님
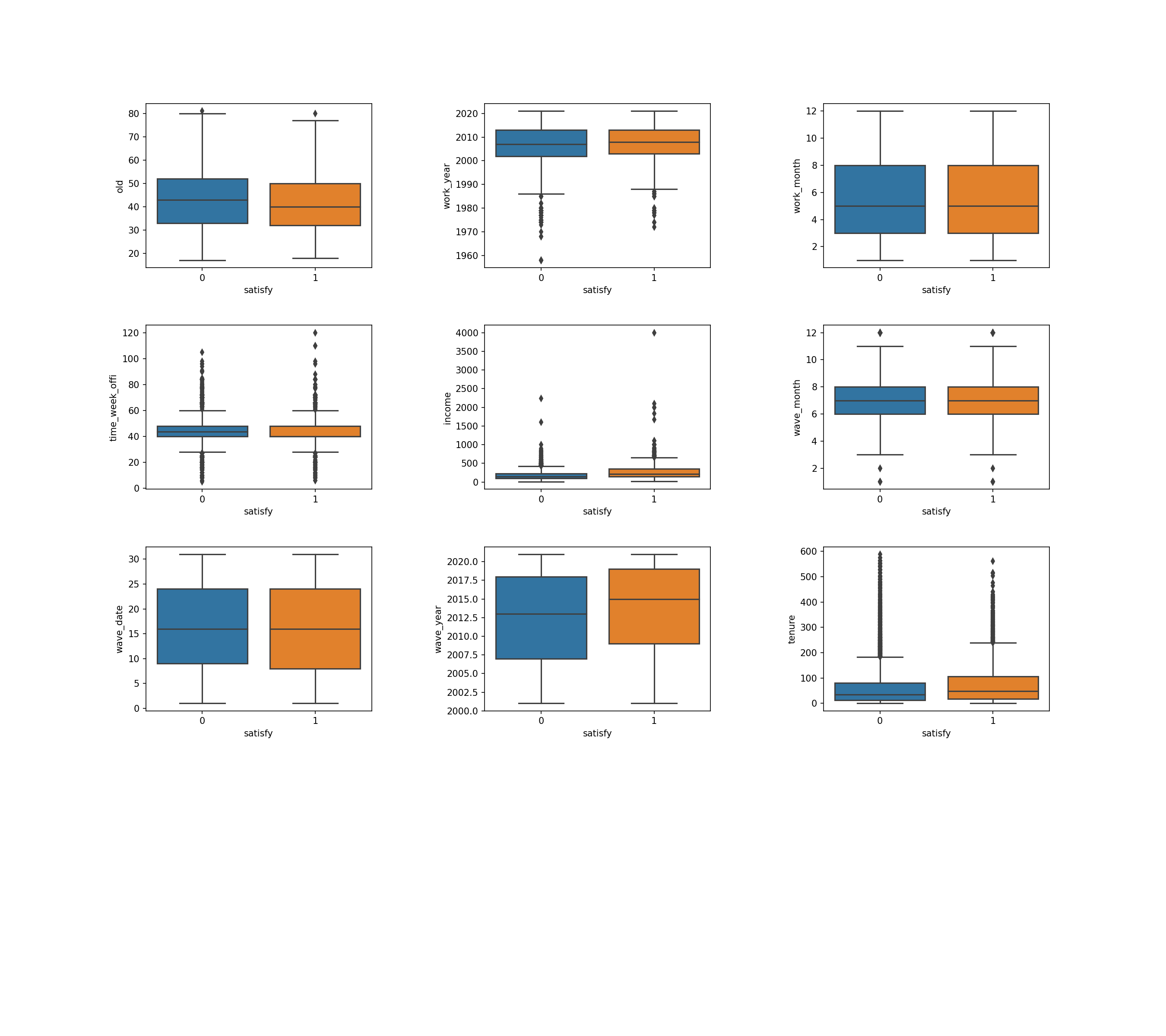
- 타겟에 따른 데이터 분포2
- 나이, 소득 등에서 타겟의 분포가 다르게 나타남
- 타겟의 분포가 다른 특성이 주요한 특성으로 예상 됨
- 직업군에 따른 데이터 분포
- 직업군에 따른 데이터분포가 서로 다르게 나타남
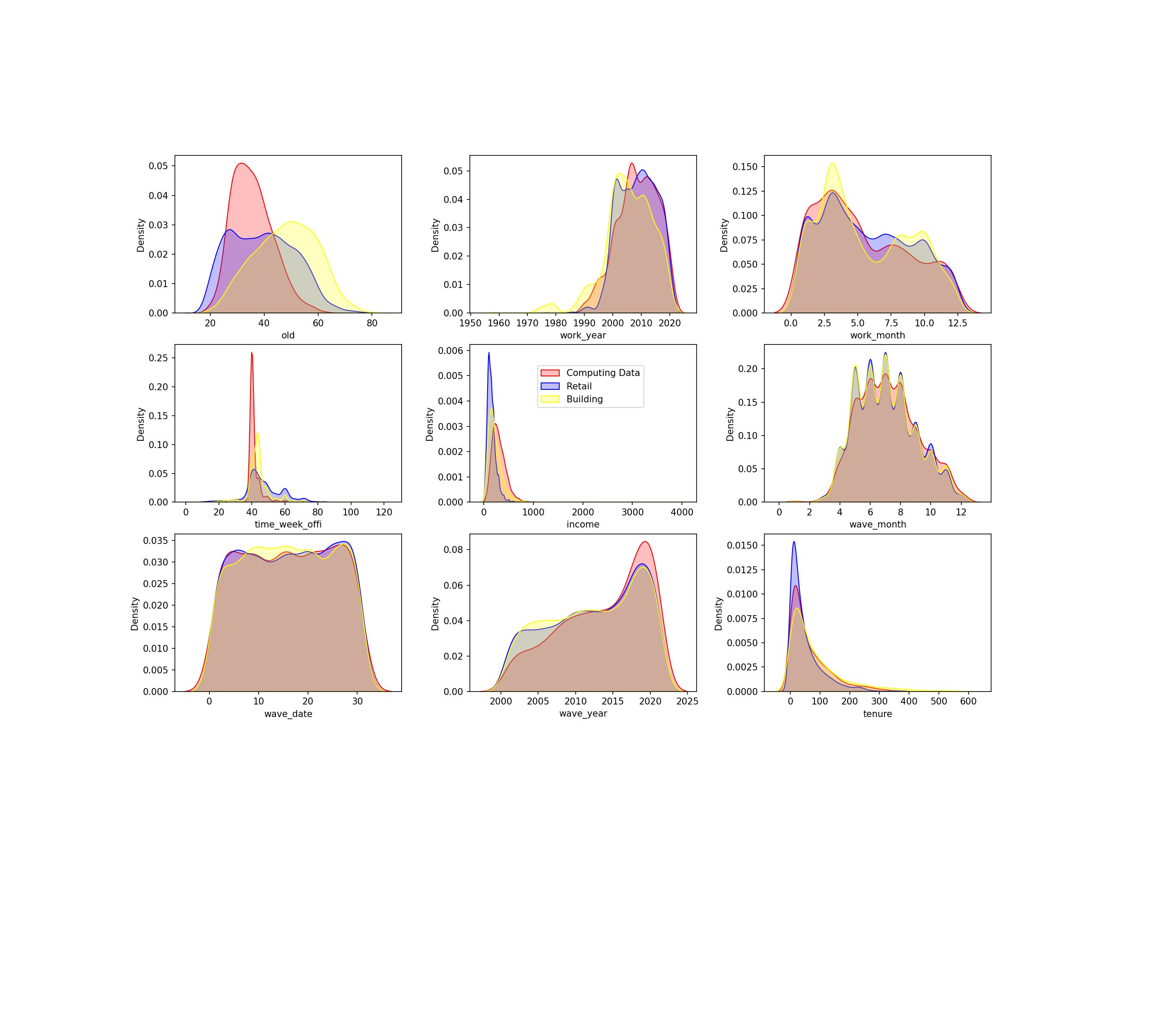
- 타겟과 직업군에 따른 데이터 분포
- 직업군에 따른 타겟의 데이터분포가 서로 다르게 나타남
- 가설 ‘직업군에 따라 만족스런 포상이 다를 것’을 예측할 수 있음
col_num = 3 # 세로 열 갯수 지정 row_num = (len(numeric_features) // col_num) + 1 fig = plt.figure(figsize=(col_num*6, row_num*4)) # fig.suptitle('Numeric Features by Job', fontsize = 24, fontweight = 'bold', y = 0.9) for i, feature in enumerate(numeric_features) : ax = plt.subplot(row_num, col_num, i+1) sns.violinplot(data=df, x=df['work_industry'], y=feature, hue=target, split=True, palette = sns.color_palette('pastel')) i += 1 plt.subplots_adjust(right=0.85, left=0.15, top=0.85, bottom=0.15, wspace=0.3, hspace=0.2) # 그래프 간격 조절 plt.show()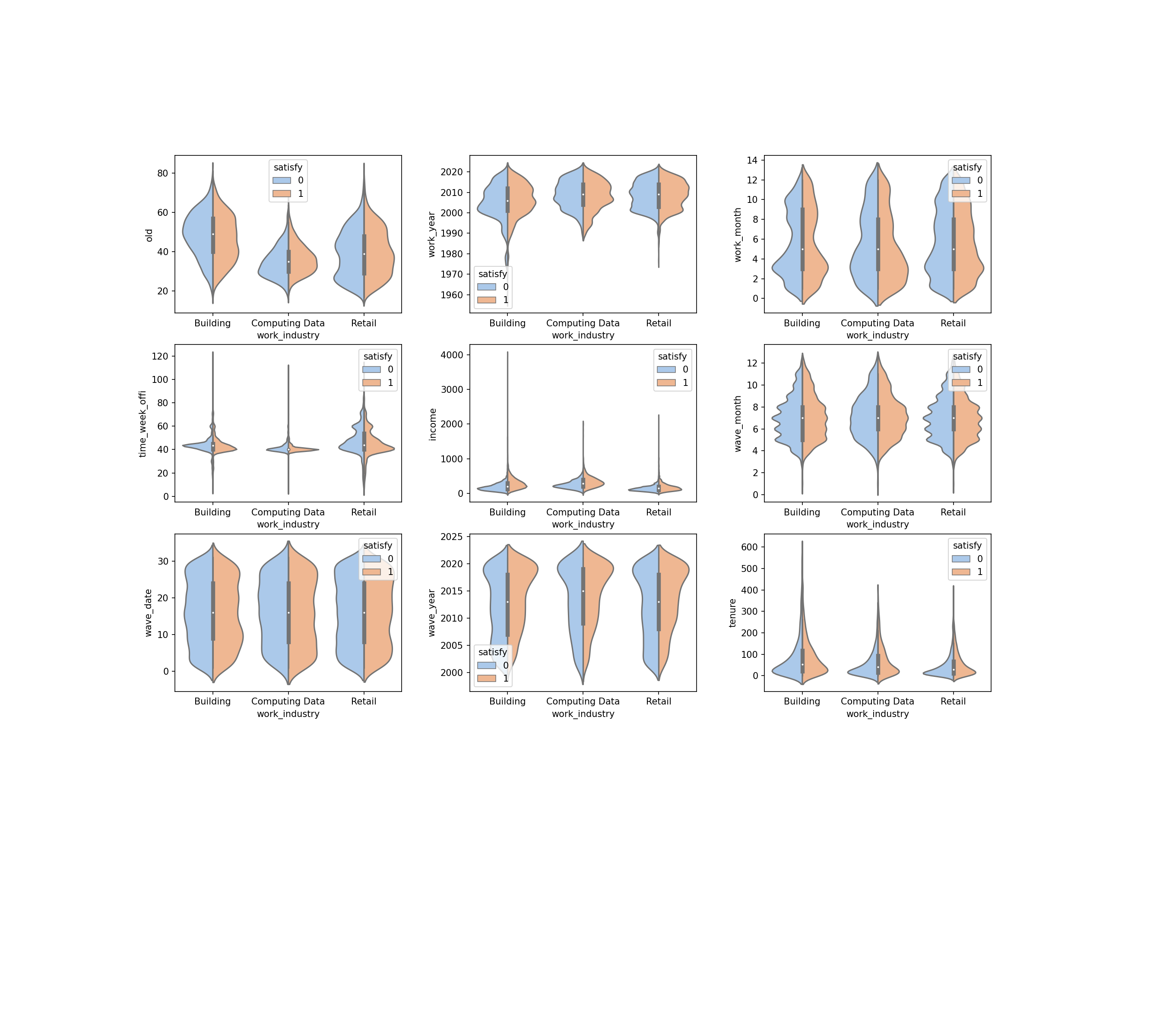
- 데이터 분포
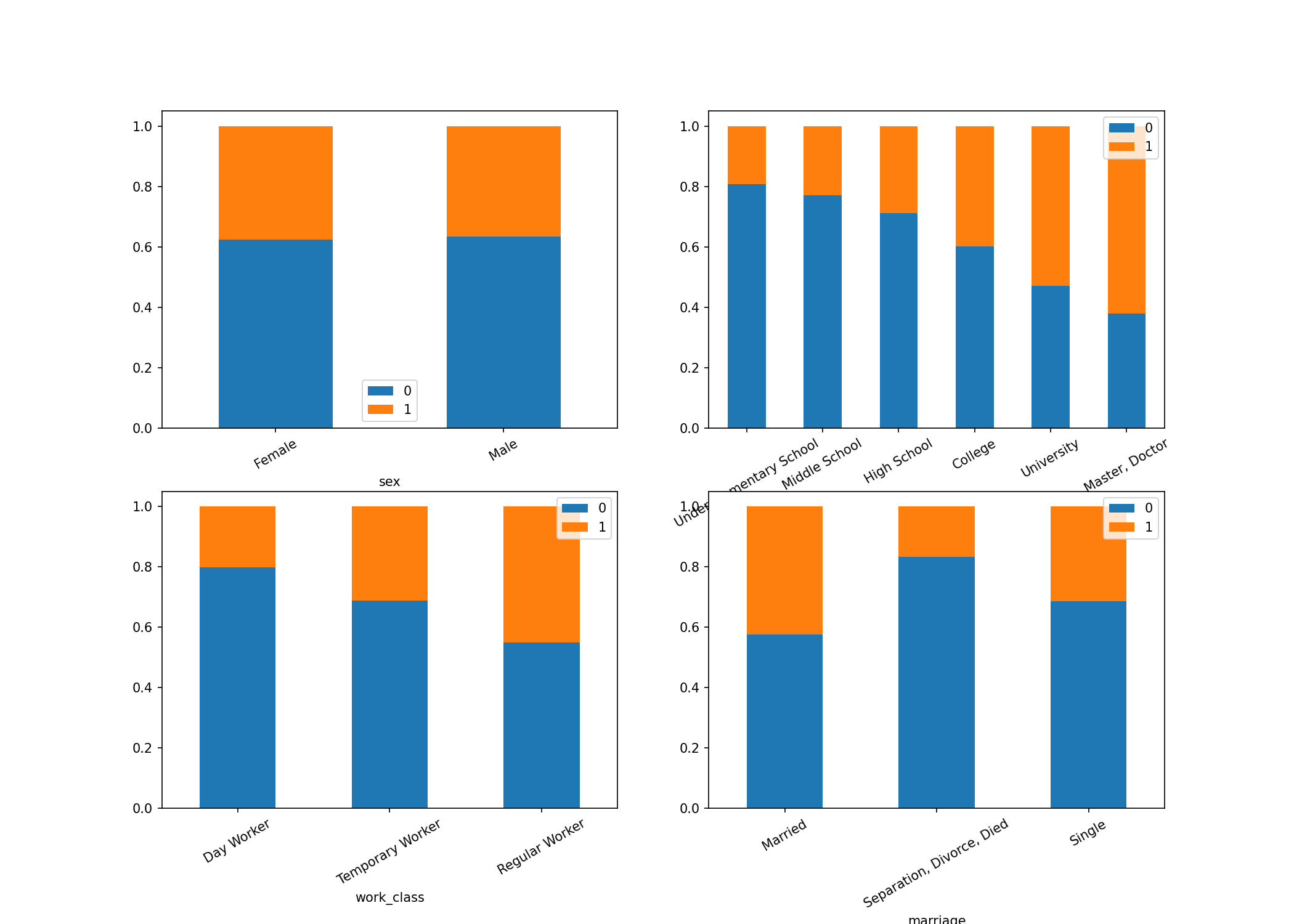
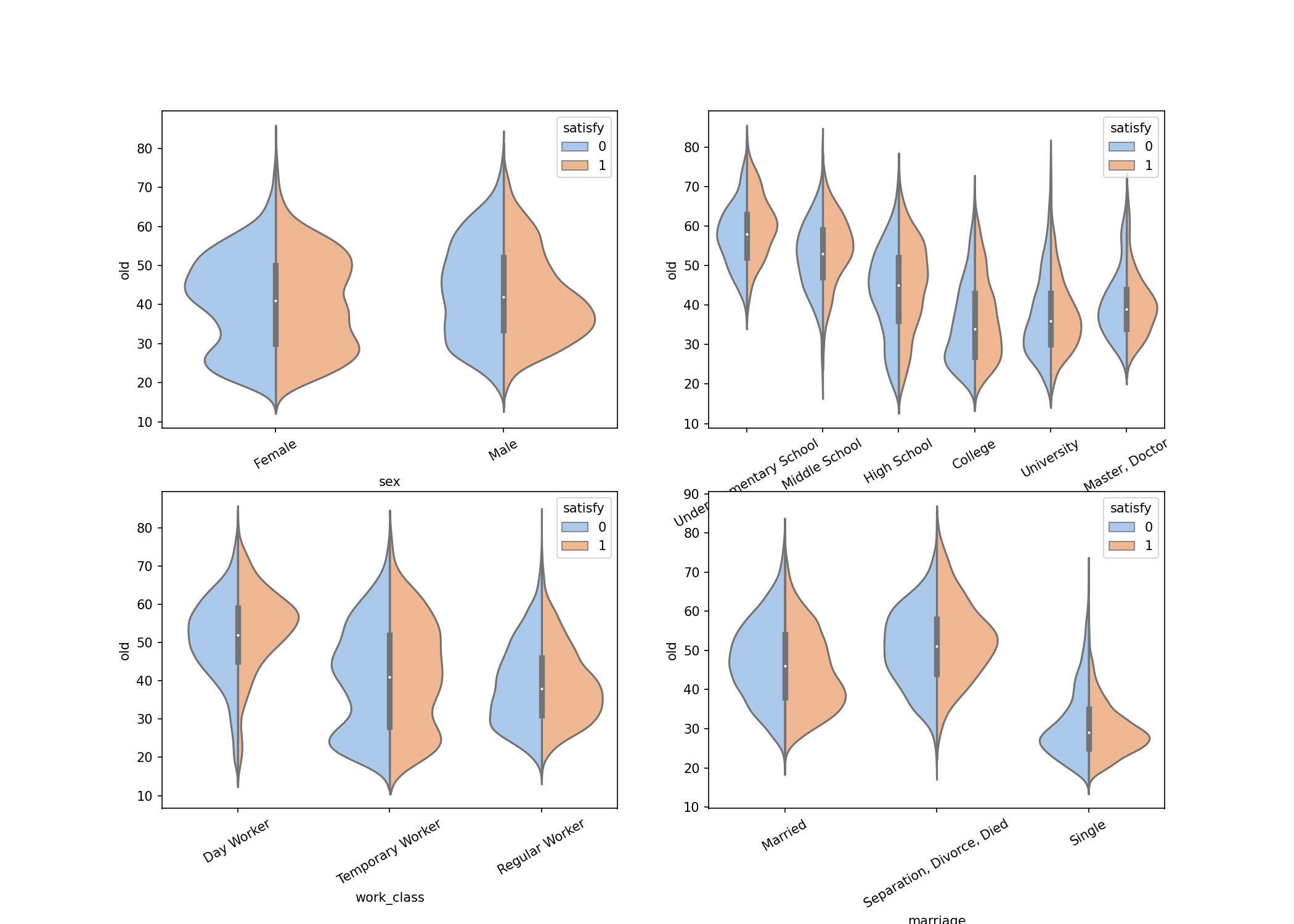
- 문자형 변수
- 막대그래프
- 교육수준에 따른 타겟의 분포가 다르게 나타남
- 바이올린 그래프
- 성별도 타겟의 분포가 다르게 나타날 수 있음
- 요인별 직무만족도 그래프
- 요인별 직무만족은 타겟을 예측하는 주요한 특성임
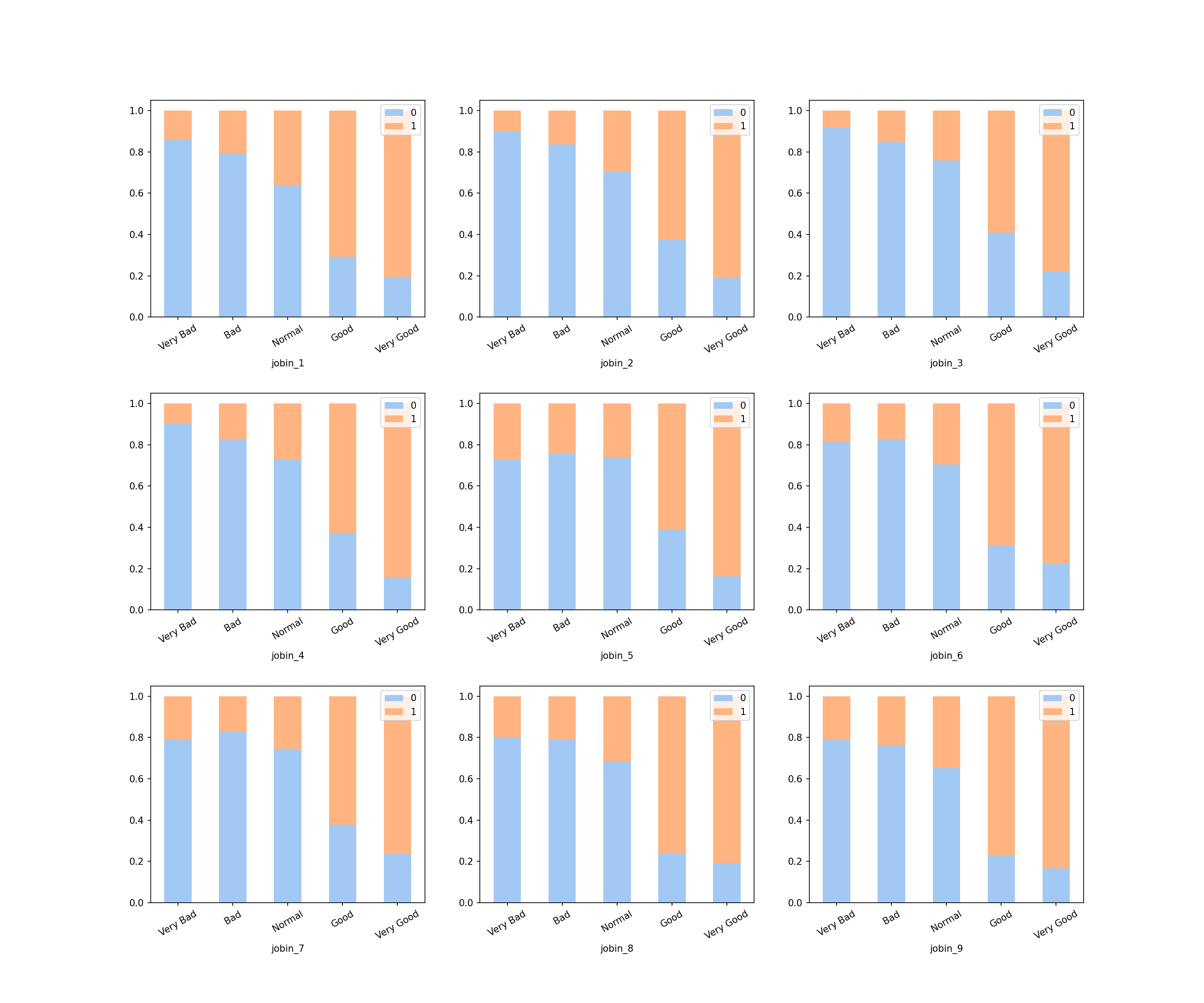
- 막대그래프
- 상관관계
- 특성사이에 강한 상관관계가 있는 부분이 있음
- 복지유무 특성들, 직업교육과 직업스킬
- 특성 사이의 강한 상관관계는 잘못된 예측을 할 수 있기 때문에 처리
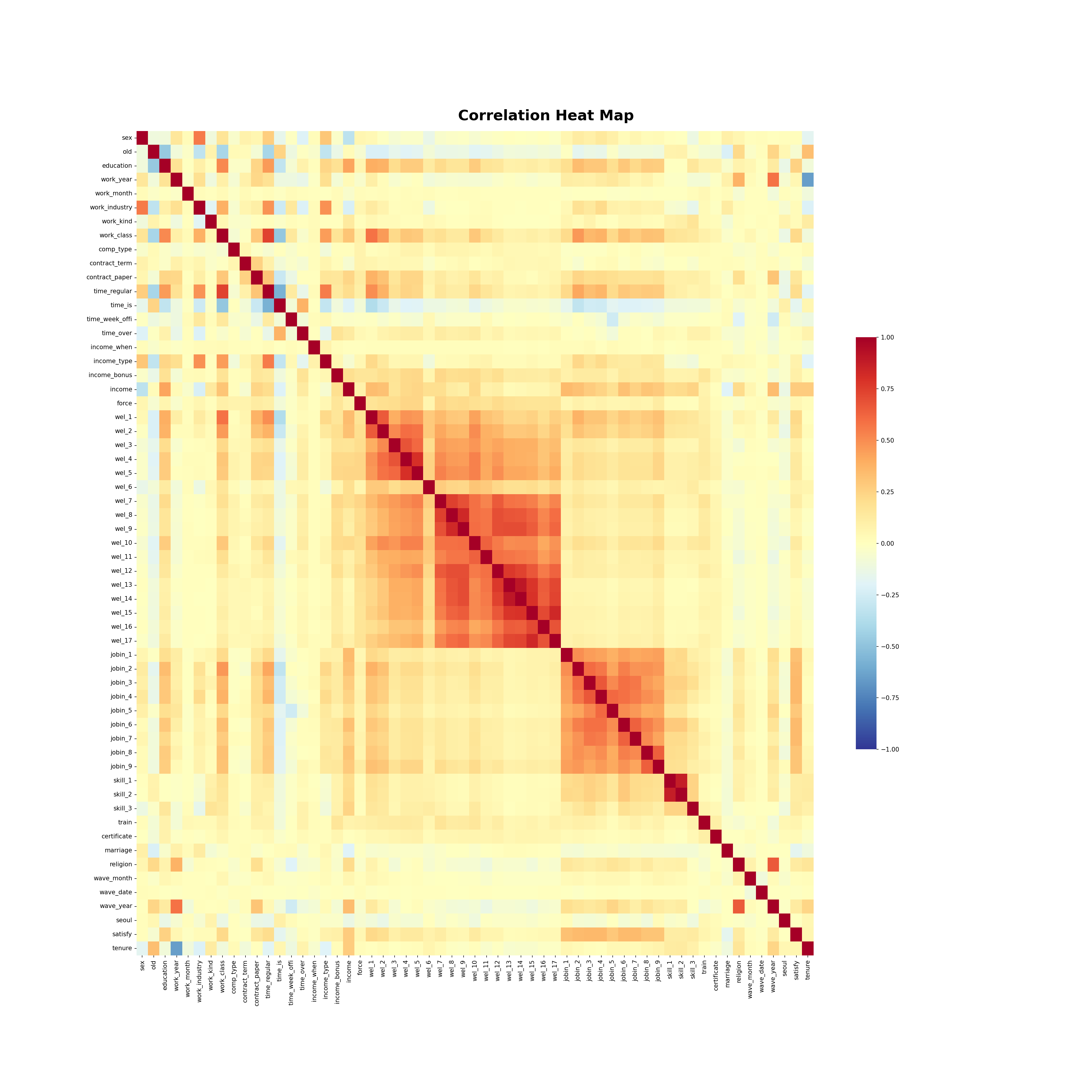
- 타겟 : ‘만족한다’라고 응답한 비율 37%
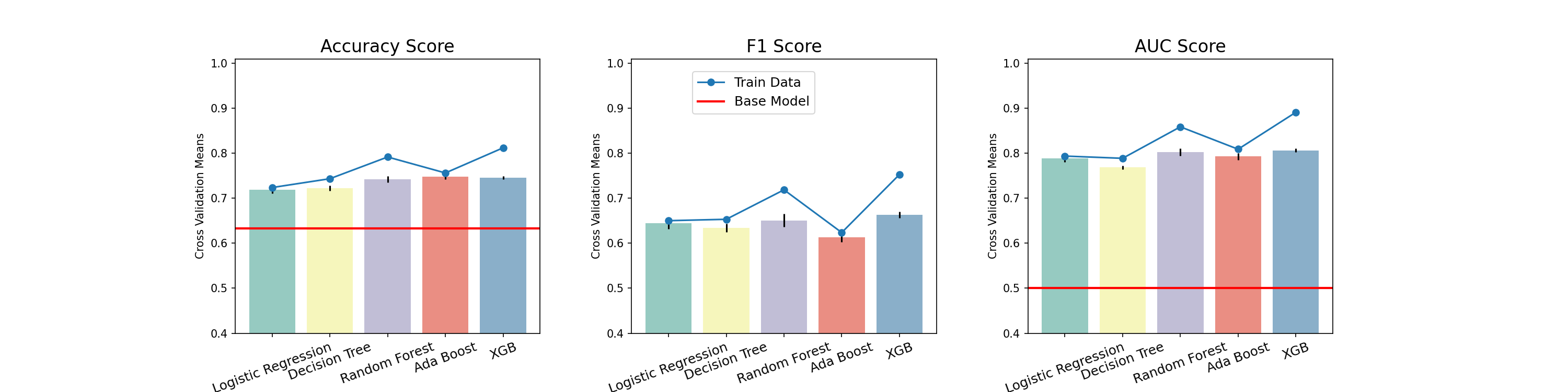
7. 모델링
- 데이터 분할 2way hold out
- train 8, test 2
- 기준모델 : 최빈값
- 정확도 : 0.633, ROC-AUC : 0.5
- 모델 선정
- Logistic Regression
- 분류모델의 가장 전통적인 방법
- 선형회귀에 시그모이드 함수 적용
- Decision Tree
- 나무기반 모델들의 기본
- 타겟 데이터의 불순도를 최소화
- Random Forest
- 앙상블 베깅기법의 대표
- 복원 추출된 샘플로 여러 모델을 병렬적으로 학습하여 합치는 과정
- AdaBoost
- 앙상블 부스팅 기법
- 순차적으로 학습
- 잘못 분류된 관측치에 가중치를 부여하여 잘 분류 되도록 보완
- XGBoost
- 앙상블 부스팅 기법
- 순차적 학습
- 잔차를 학습하여 잔차가 큰 관측치를 더 학습하여 보완
- Logistic Regression
- 기본값 모델
# Default Model Pipes
# https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
lr_pipe = make_pipeline(
OrdinalEncoder(),
StandardScaler(),
LogisticRegression(random_state = rand_seed
, class_weight = 'balanced'
),
)
# https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
dt_pipe = make_pipeline(
OrdinalEncoder(),
DecisionTreeClassifier(random_state = rand_seed
, class_weight = 'balanced'
),
)
# https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier
rf_pipe = make_pipeline(
OrdinalEncoder(),
RandomForestClassifier(random_state = rand_seed
, class_weight = 'balanced'
),
)
# https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html#sklearn.ensemble.AdaBoostClassifier
ad_pipe = make_pipeline(
OrdinalEncoder(),
StandardScaler(),
AdaBoostClassifier(random_state = rand_seed
),
)
# https://xgboost.readthedocs.io/en/latest/parameter.html
xg_pipe = make_pipeline(
OrdinalEncoder(),
XGBClassifier(random_state = rand_seed
, scale_pos_weight = all_y_train.value_counts()[0] / all_y_train.value_counts()[1]
),
)
model_list = ['Logistic Regression', 'Decision Tree', 'Random Forest', 'Ada Boost', 'XGB']
score_list = ['Accuracy', 'F1', 'AUC']
model_initial = ['lr', 'dt', 'rf', 'ad', 'xg']
# 모델 학습
for i, model in enumerate(model_initial) :
print(f'✅ {model_list[i]}')
globals()[f'{model}_pipe'].fit(all_X_train, all_y_train)
globals()[f'{model}_pipe_score_def'] = print_score(globals()[f'{model}_pipe'], all_X_train, all_y_train)
- 불균형한 타겟을 처리하기 위한 파라미터 추가
- Logistic Regression : L2 패널티 정규화 기본값
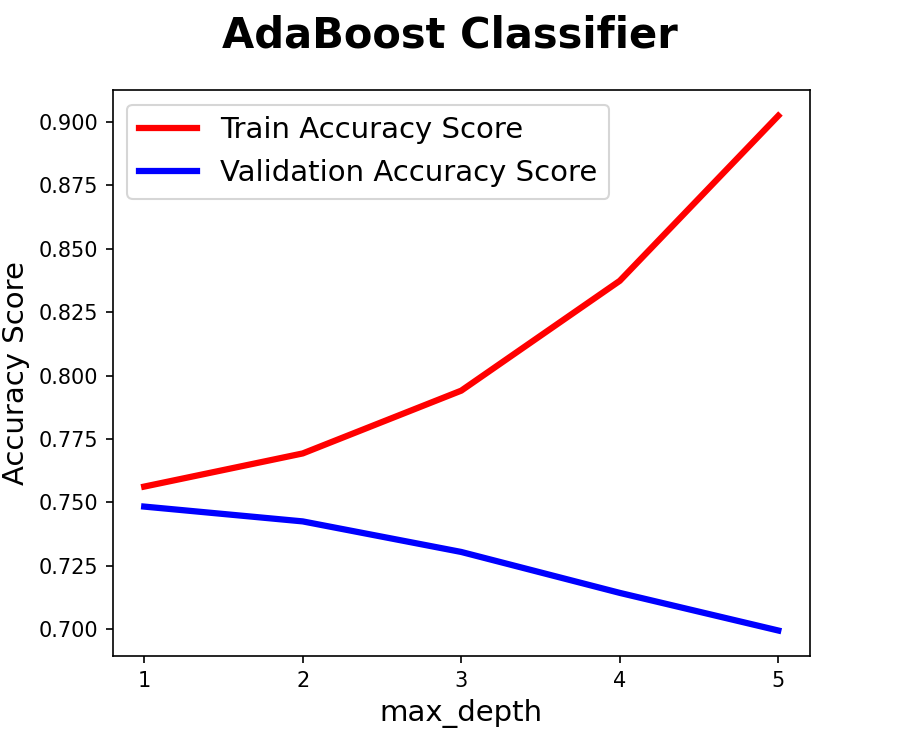
- AdaBoost : Decision Tree max_depth=1 기본값
- XGBoost : max_depth=6 기본값
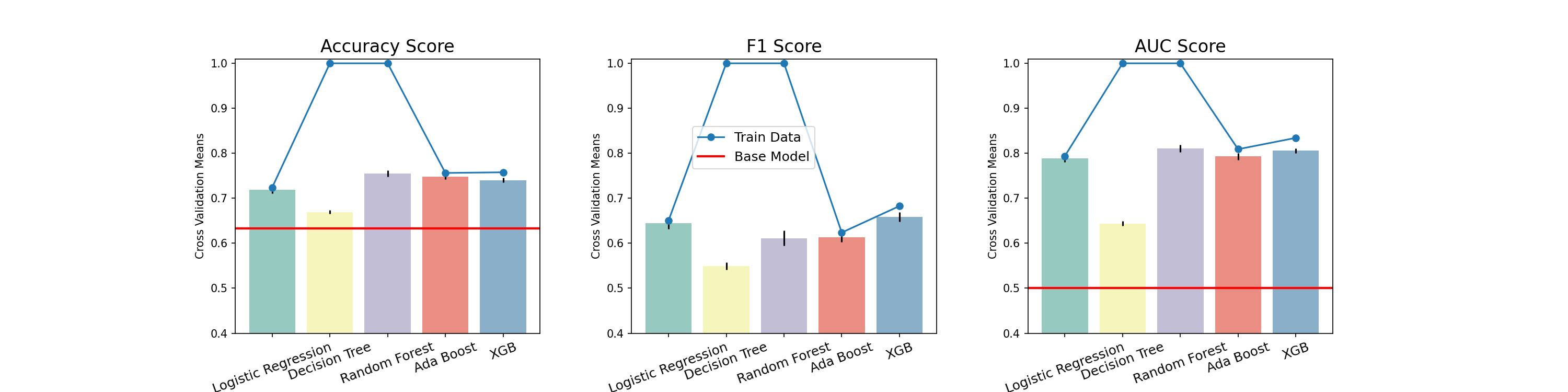
- 하이퍼파라미터 튜닝1
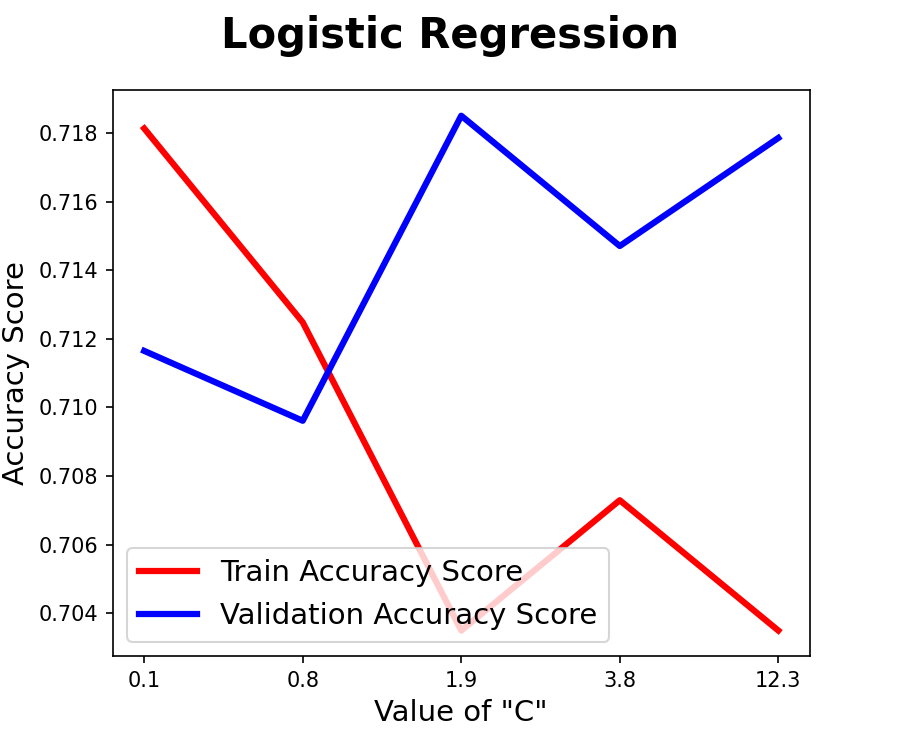
- 러닝커브
- Logistic Regression
- C : 기본설정된 L2패널티의 정규화 강도, 작을수록 강한 정규화
- 기본값 1 유지
- max_depth
- 결정나무의 최대 깊이, 클수록 과적합이 우려
- Decision Tree : 약4에서 최적화, 7이 넘어가면 과적합 우려
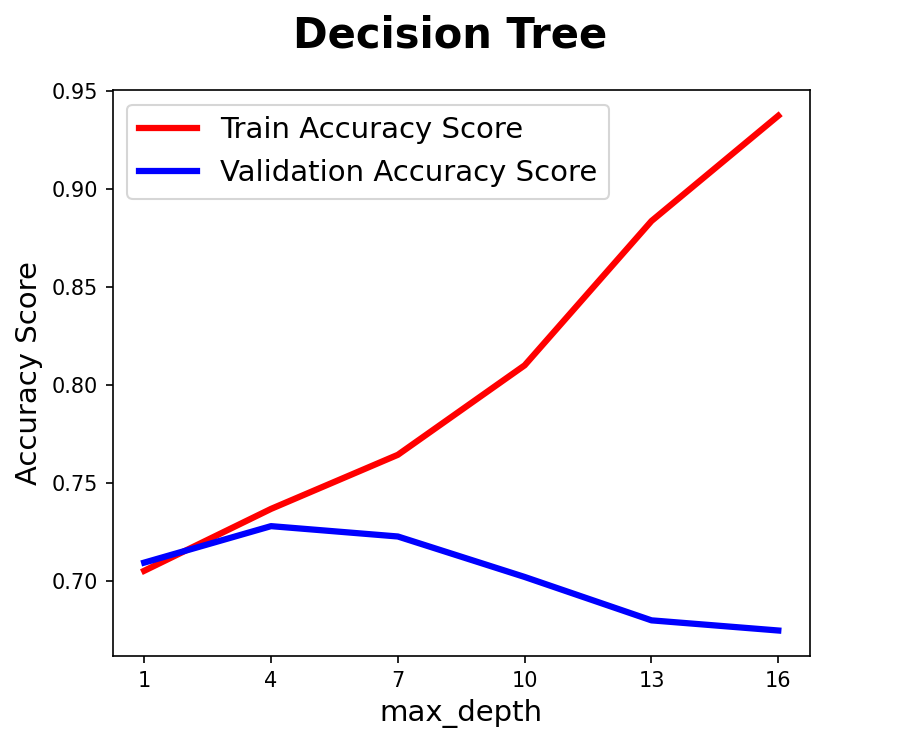
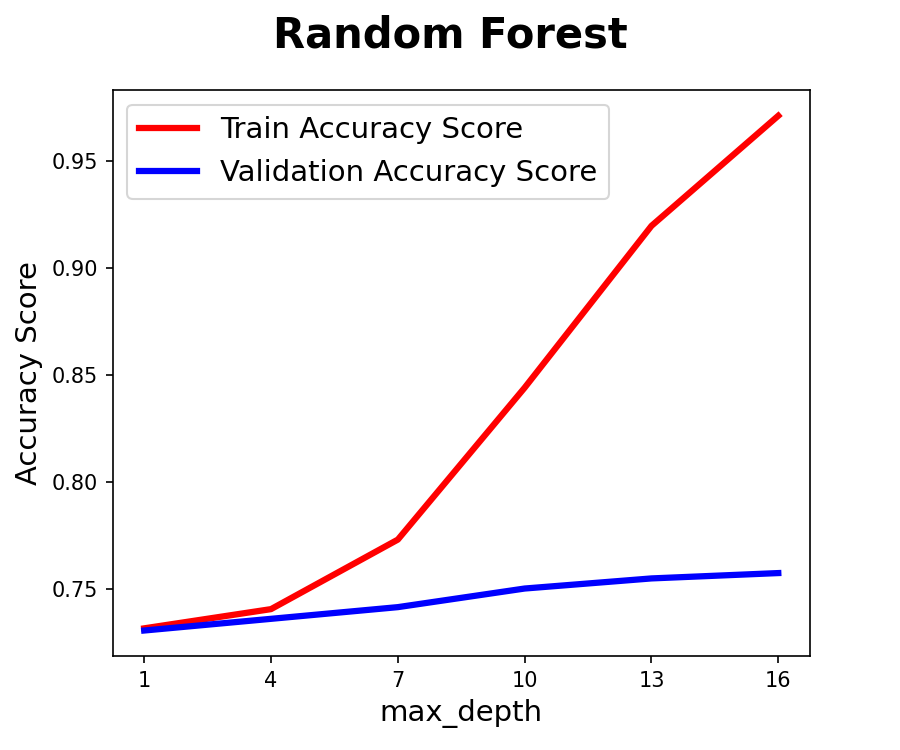
- Random Forest : 약5에서 최적화, 8이 넘어가면 과적합 우려
- AdaBoost : 1에서 최적화, 기본값 유지
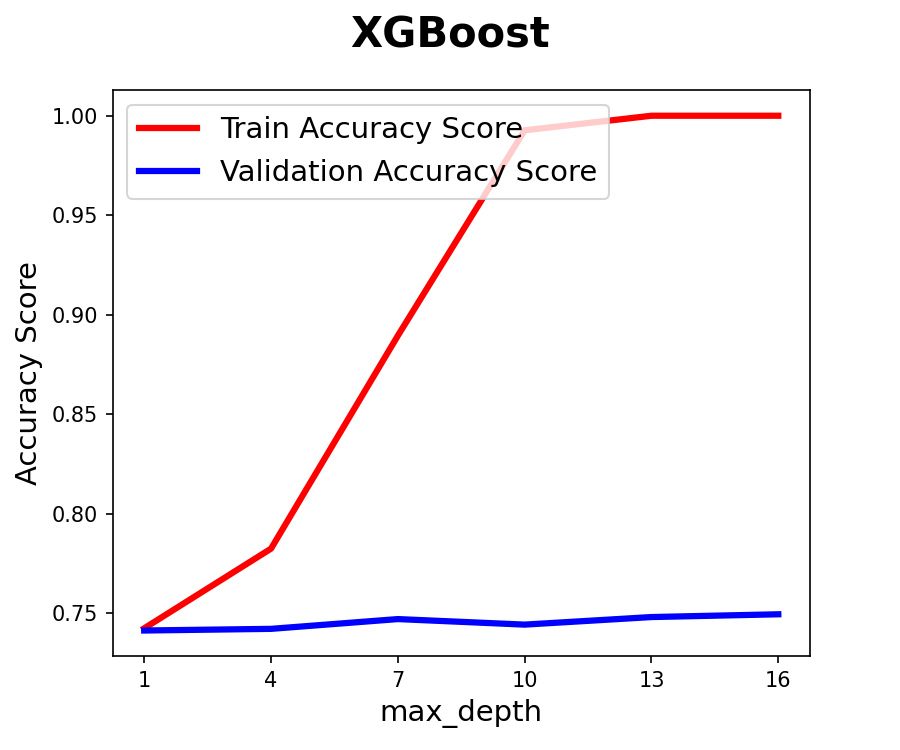
- XGBoost : 약3에서 최적화, 5 넘어가면 과적합 우려
- Logistic Regression
- RandomizedSearchCV
- GridSearchCV는 지정한 파라미터의 모든 조합을 검색
- 찾고자 하는 파라미터의 범위가 넓을 경우 시간이 오래걸림
- 처음 분석하는 데이터이기 때문에 폭넓은 범위를 효율적으로 찾을 수 있는 RandomizedSearchCV 선택
- Decision Tree : max_depth: 5
- Random Forest : max_depth: 8
- XGBoost : max_depth: 5
- GridSearchCV는 지정한 파라미터의 모든 조합을 검색
- Random Forest, XGBoost는 과적합 여지가 있음
- 러닝커브
- 하이퍼파라미터 튜닝2
- 러닝커브
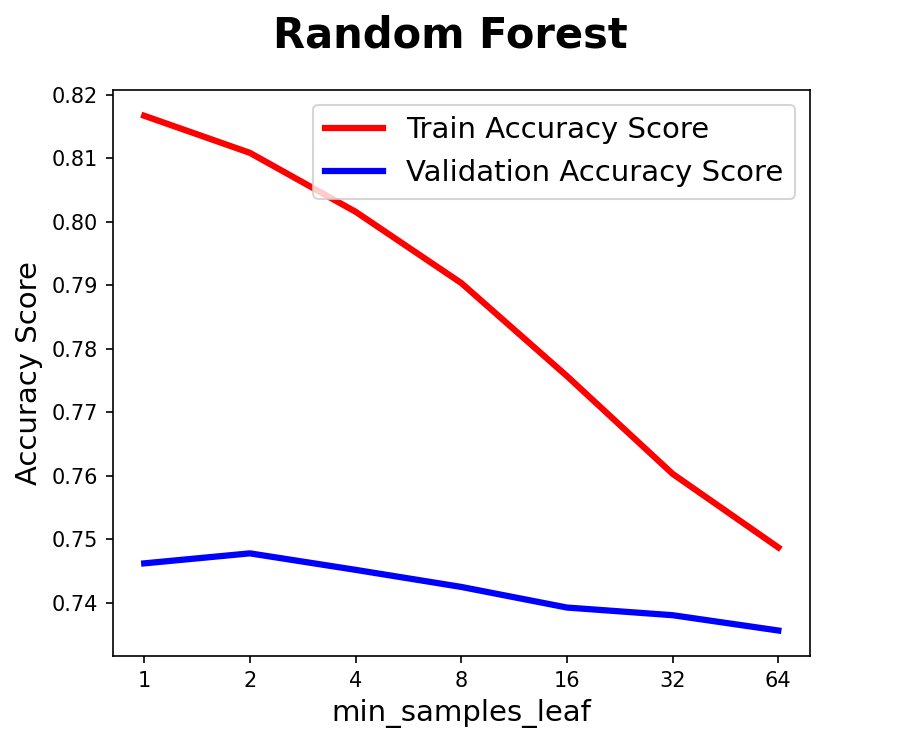
- Random Forest
- min_samples_leaf : 리프노드에 필요한 최소 샘플 수, 클수록 모델 단순화
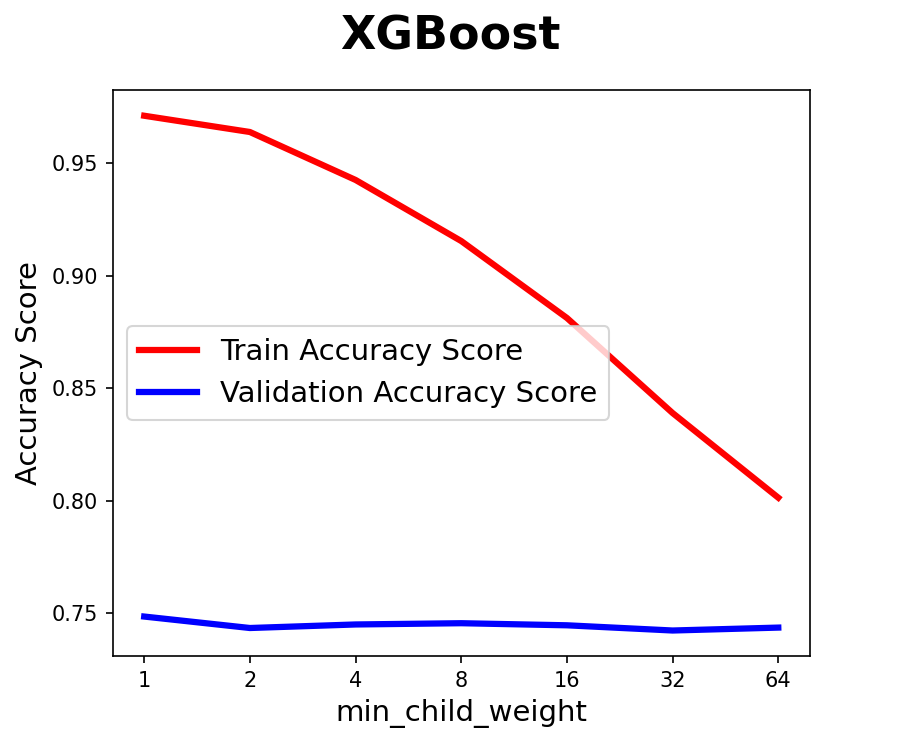
- XGBoost
- min_child_weight : 하위 항목(child)에 필요한 최소한의 객체 가중치(weight), 클수록 모델 단순화
- Random Forest
- RandomizedSearchCV
- Random Forest
- min_samples_leaf: 1
- max_depth: 7
- XGBoost
- min_child_weight: 64
- max_depth: 6
- Random Forest
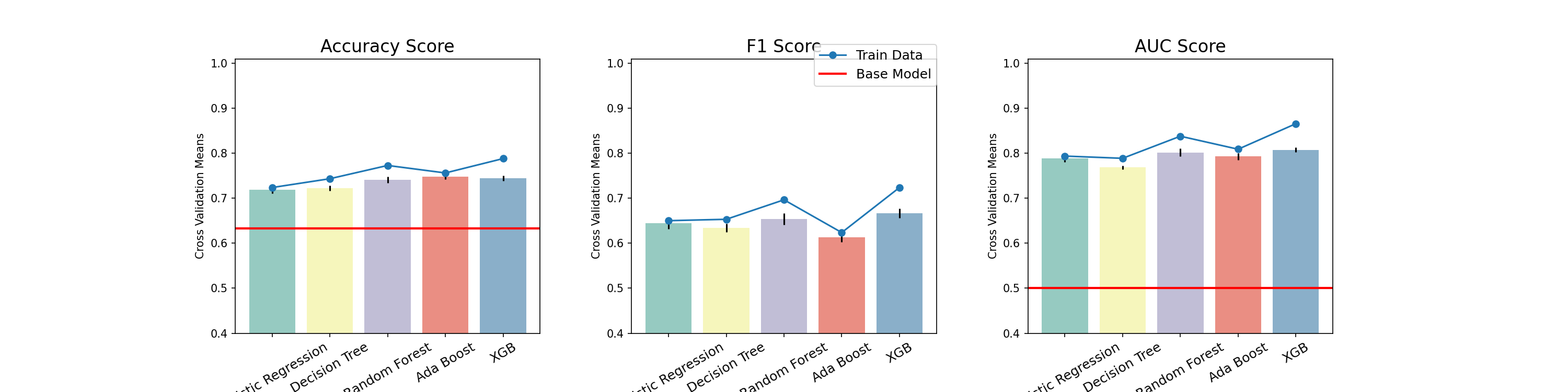
- 러닝커브
- 최종모델
- Accuracy, F1, ROC-AUC 에서 고르게 높은 점수를 기록한 Random Forest, XGBoost을 최종 모델로 선택
- 평가데이터셋에 최종모델 학습
- 기준모델보다 성능이 뛰어난 최종모델
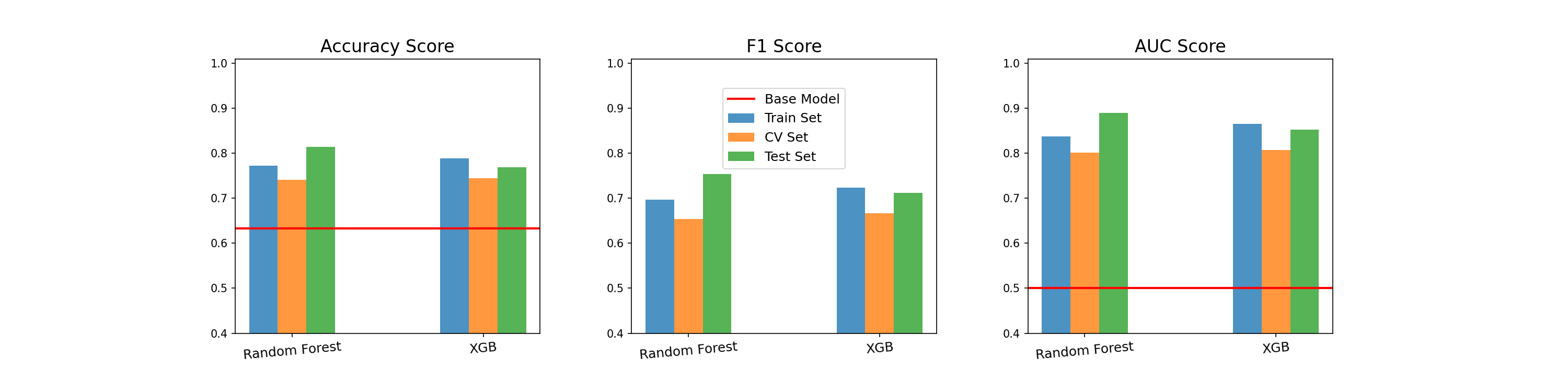
8. 모델 해석
- 모델 해석
- 3가지 직업군 타겟 확인
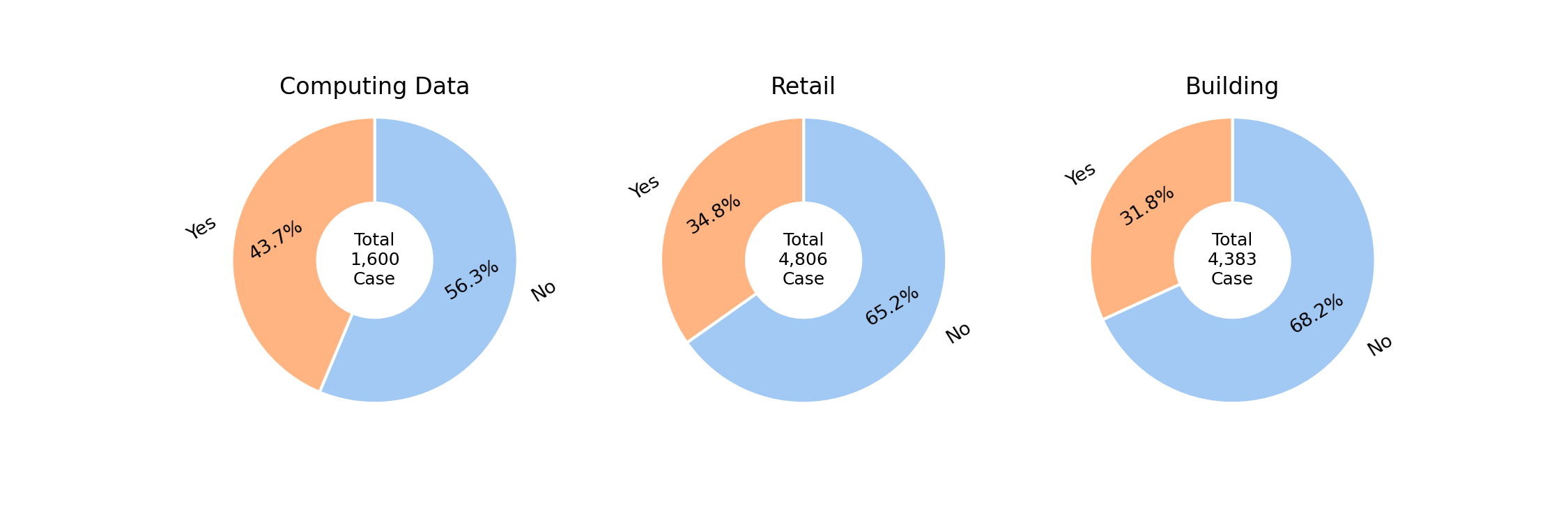
- 3가지 직업군에 따라 모델 학습
# rf_max_depth 7 # rf_min_samples_leaf 1 # xg_max_depth 6 # xg_min_child_weight 64 def rf_pipe_fit(X_train, y_train): """ Random Forest Classifier 파이프를 만들고 모델에 학습하는 함수 """ rf_pipe = make_pipeline( OrdinalEncoder(), RandomForestClassifier(random_state = rand_seed , class_weight = 'balanced' , max_depth = int(best_params_read.loc['rf_max_depth'][0]) , min_samples_leaf = int(best_params_read.loc['rf_min_samples_leaf'][0]) ), ) return rf_pipe.fit(X_train, y_train) def xg_pipe_fit(X_train, y_train): """ XGBClassifier 파이프를 만들고 모델에 학습하는 함수 """ xg_pipe = make_pipeline( OrdinalEncoder(), XGBClassifier(random_state = rand_seed , scale_pos_weight = y_train.value_counts()[0] / y_train.value_counts()[1] , max_depth = int(best_params_read.loc['xg_max_depth'][0]) , min_child_weight = int(best_params_read.loc['xg_min_child_weight'][0]) ), ) return xg_pipe.fit(X_train, y_train)- 모든 직군에서 ‘월평균소득’과 ‘혼인상태’는 공통으로 중요한 특성
# 컴퓨터 직업군 소득, 혼인상태 com_pdp = PartialDependenceDisplay.from_estimator(com_rf_step_model, com_rf_X_test_enc, ["income", "marriage"], ax=ax, line_kw={"color": "blue"}) # 판매업 직업군 소득, 혼인상태 ret_pdp = PartialDependenceDisplay.from_estimator(ret_rf_step_model, ret_rf_X_test_enc, ["income", "marriage"], ax=ax, line_kw={"color": "red"}) # 건설업 직업군 소득, 혼인상태 bld_pdp = PartialDependenceDisplay.from_estimator(bld_rf_step_model, bld_rf_X_test_enc, ["income", "marriage"], ax=ax, line_kw={"color": "orange"}) fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6)) com_pdp.plot(ax=[ax1, ax2], line_kw={"label": "com_pdp", "color": "blue"}) ret_pdp.plot(ax=[ax1, ax2], line_kw={"label": "ret_pdp", "color": "red"}) bld_pdp.plot(ax=[ax1, ax2], line_kw={"label": "bld_pdp", "color": "orange"}) ax1.set_ylim(0.35,0.65) ax2.set_ylim(0.3,0.6) ax1.legend(['Computing Data', 'Retail', 'Building']) ax2.legend(['Computing Data', 'Retail', 'Building'])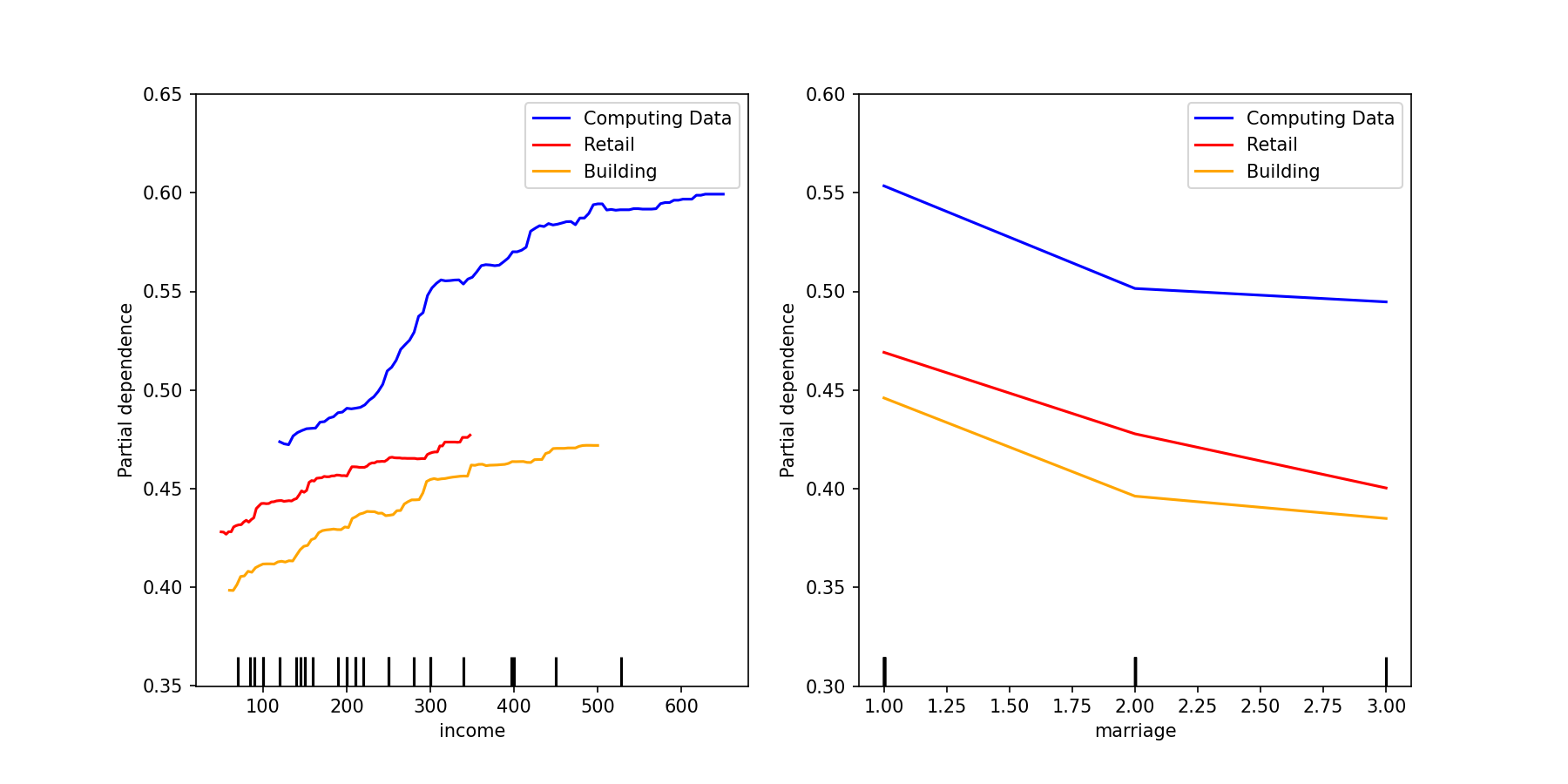
- 컴퓨터 직군 중요 특성
- 요인별직무만족도-6.개인의발전가능성
- 요인별직무만족도-8.인사고과의공정성
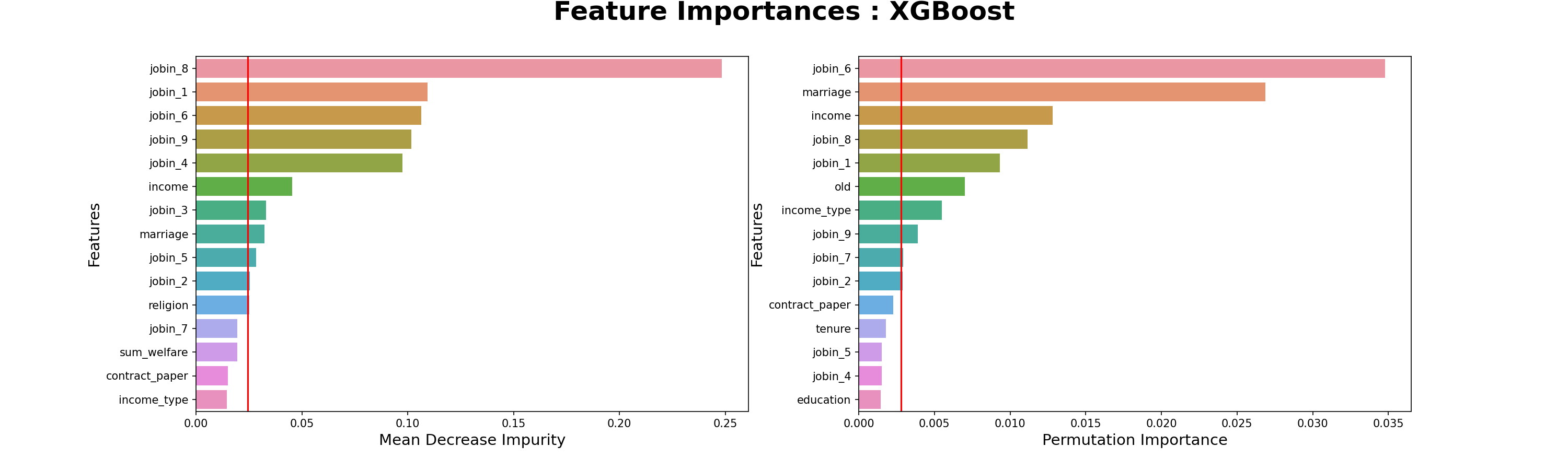
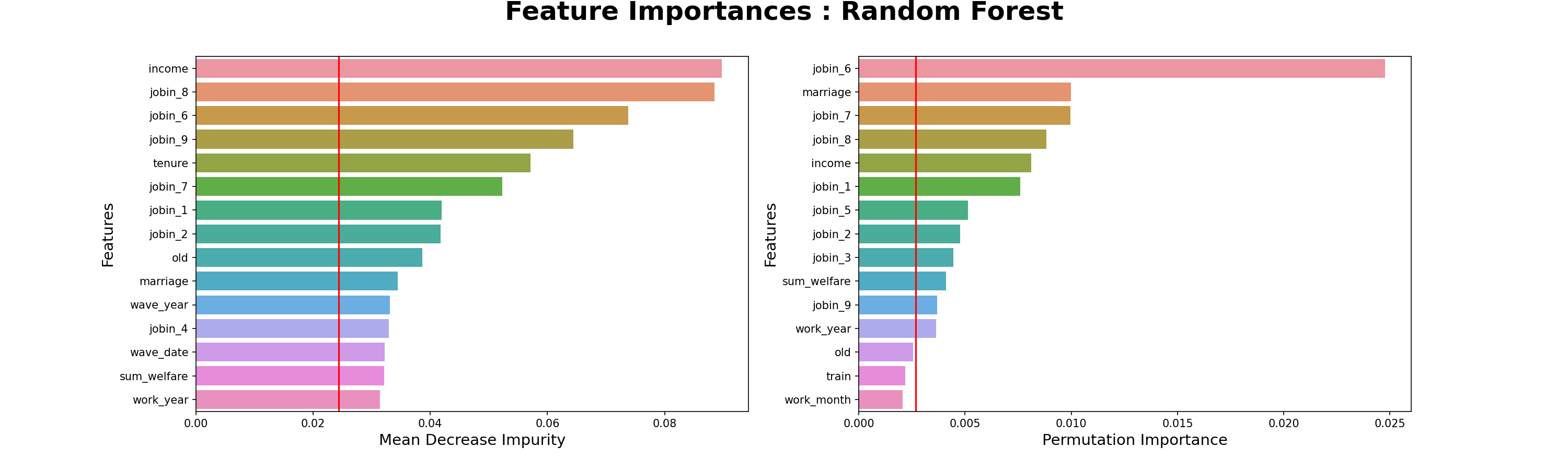
- 판매업 직군 중요 특성
- 요인별직무만족도-7.의사소통및인간관계
- 요인별직무만족도-4.근무환경
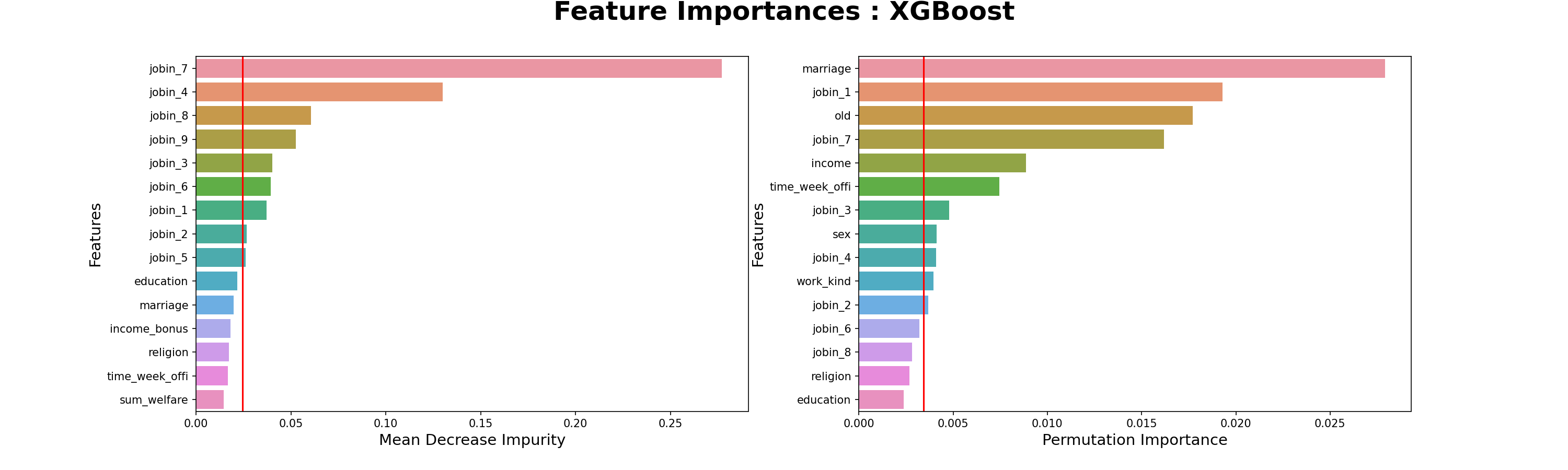
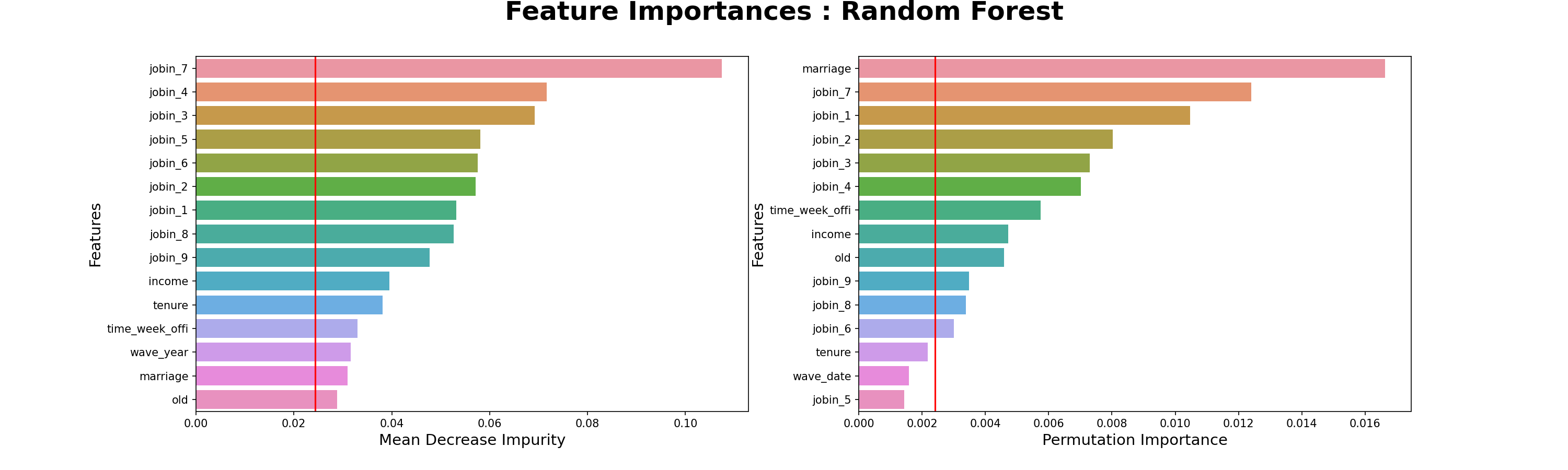
- 건설업 직군 중요 특성
- 요인별직무만족도-3.하고있는일의내용
- 요인별직무만족도-5.근로시간
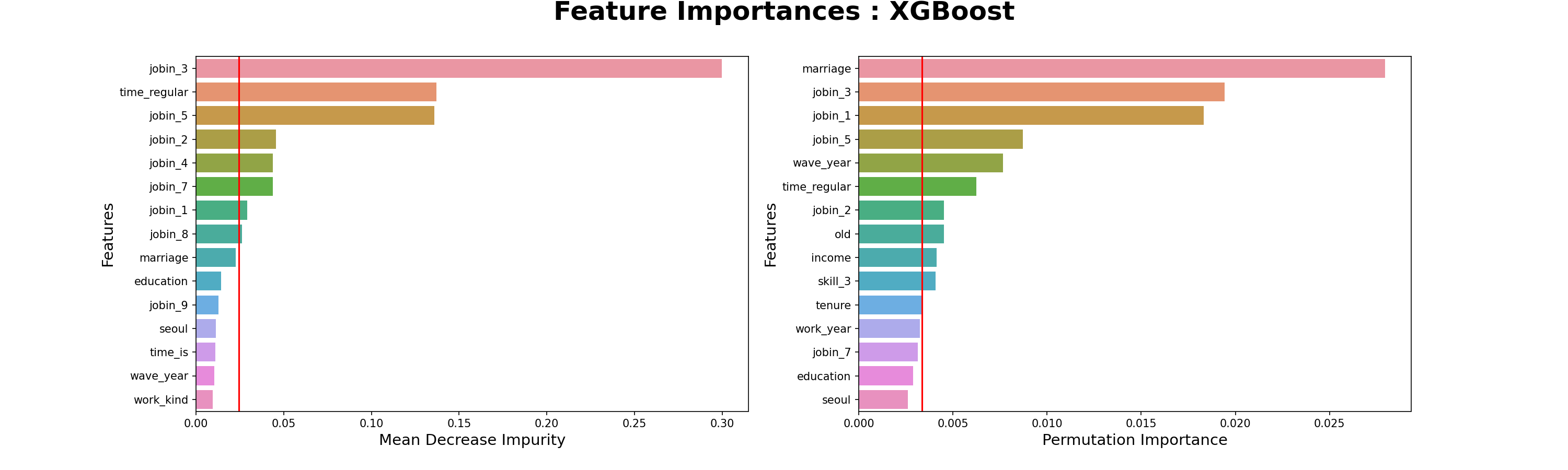
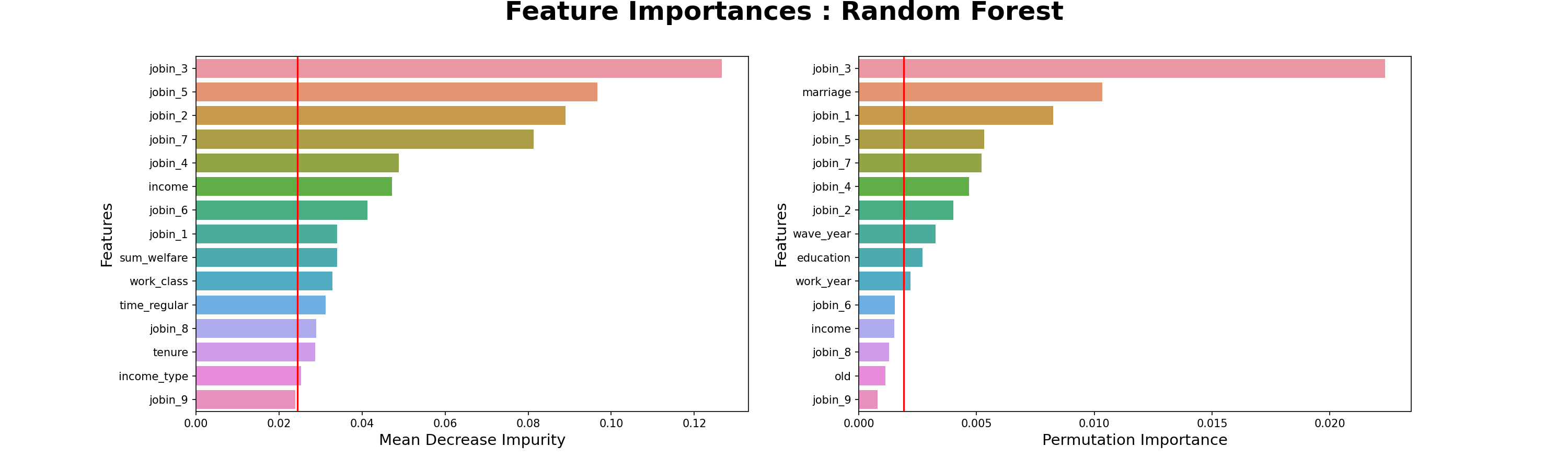
- 직군별 가장 중요한 특성
- 컴퓨터 직군 : ‘직무만족도-6.개인의발전가능성’
- 판매업 직군 : ‘직무만족도-7.의사소통및인간관계’
- 건설업 직군 : ‘직무만족도-3.하고있는일의내용’
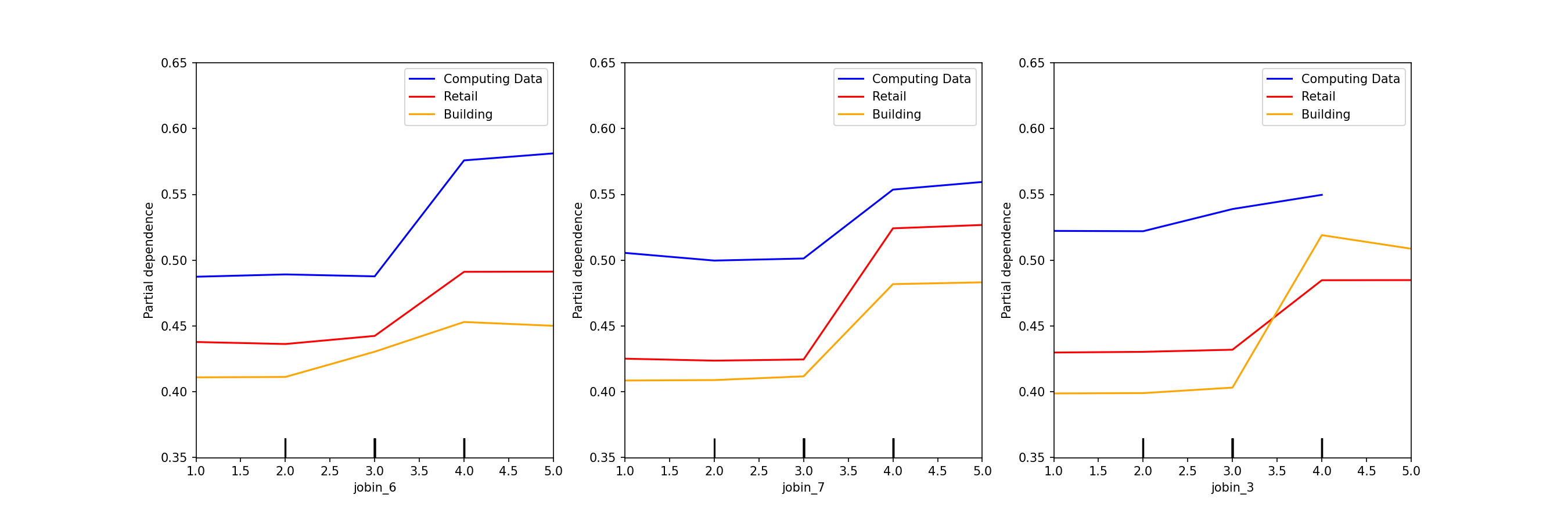
- 건설업 관력 직군의 ‘직무만족도-3.하고있는일의내용’ - ‘직무만족도-5.근로시간’
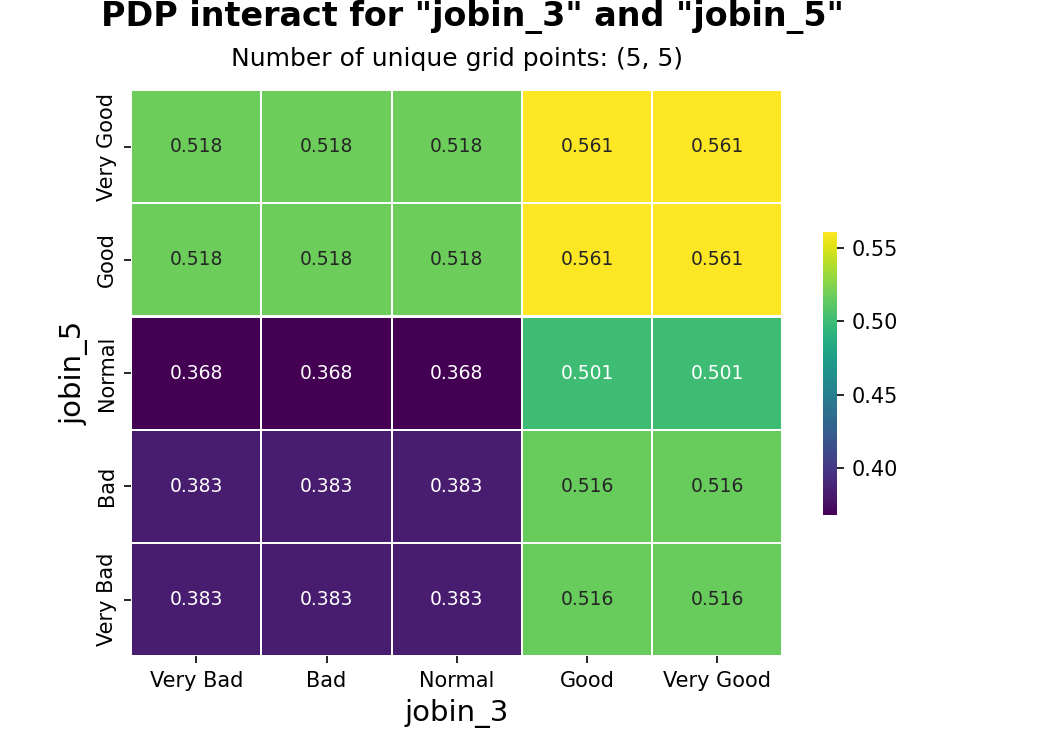
9. 결론
- 모든 직업군에서 공통으로 ‘소득’과 ‘혼인상태’는 ‘만족한다’라고 응답할 확률을 올리는 중요한 특성
- 평균 소득이 낮은 ‘판매직’📌에게 ‘소득’을 올려주는 포상이 다른 직군보다 효과적으로 예상 됨
- 싱글 비율이 가장 높은 ‘건설직’🎉에게 ‘혼인상태’를 개선해주는 포상이 다른 직군보다 효과적으로 예상 됨
- 컴퓨터 직군
- ‘개인의 발전가능성’, ‘인사고과의 공정성’이 중요한 특성
- 공정한 성과급을 지급하고, 각종 연수나 교육 등이 효과적으로 예상 됨
- 판매업 직군
- ‘의사소통 및 인간관계’, ‘근무환경’이 중요한 특성
- 직장 내 소통을 원활하게 할 수 있는 각종 단합대회, 근무환경을 개선시킬 수 있는 환경개선 사업 등이 효과적으로 예상 됨
- 건설업 직군
- ‘하고 있는 일의 내용’, ‘근로 시간’이 중요한 특성
- 업무 순환제도를 이용하거나, 조기퇴근 등이 효과적으로 예상 됨
- 한계점
- 타겟인 '전반적 생활만족'과 포상제도의 연관성 부족
- 선행연구 조사를 통하여 '포상제도'와 '만족도'의 관계 연구 필요
- 모델 최적화가 부족
- 데이터에 맞는 알맞는 하이퍼파라미터 튜닝 노력
- 서포트벡터머신 등 새로운 알고리즘 적용 필요
- 패널데이터의 통합분석
- 시계열 특성을 통제해야 함
- 타겟인 '전반적 생활만족'과 포상제도의 연관성 부족


댓글남기기