
AI 부트캠프 12주 : Section 3 Project

AI 부트캠프 12주차 : Section 3 Project
드디어 딥러닝을 활용한 프로젝트를 진행한다.
Section3를 시작하면서 chatGPT가 열풍을 일으켰다.
나도 chatGPT를 만들 수 있을까?
주간회고
더 공부가 필요한 부분
- 최신모델에 대한 정확한 이해와 사전학습, 파인튜닝 적용 연습
- 대규모 모델을 학습하기 위한 파라미터 조정과 실습
5F 회고
-
사실(Fact)
인공신경망 모델, 특히 트랜스포머 모델을 활용하여 작은 AI챗봇을 만드는 프로젝트를 수행하였다. -
느낌(Feeling)
작은 규모의 프로젝트지만 챗GPT와 같은 최신 생성형 AI 언어모델에 한걸음 다가간것 같아 뿌듯하고, 나도 언젠가는 챗GPT를 만들어 보고 싶다는 욕심이 생겼다. -
교훈(Finding)
보는 것과 직접 만드는 것은 차이가 많은 것 같다. 프로젝트를 수행하며 직접 모델을 구현해보는 것이 100번 학습하는 것보다 자신감 향상에 도움이 된다. -
향후 행동(Future action)
모델에 대한 이해를 확장하기 위한 학습과 직접 모델을 구현해보는 투트랙 전략으로 공부할 것이다. -
피드백(Feedback)
내용
완성영상 보기
프로젝트 계획 및 과정
1. 프로젝트 계획
| 날짜 | 내용 |
|---|---|
| 3/8 (수) | • 프로젝트 START🚀 • 1. 프로젝트 계획 • 2. 주제선정 |
| 3/9 (목) | • 3. 주제관련 아티클 조사 • 4. 데이터 선정 • 5. 데이터 전처리 • 6. 탐색적 데이터분석 |
| 3/10 (금) | • 7. 모델링 |
| 3/11 (토) | • 8. 모델 해석 |
| 3/12 (일) | • PPT 슬라이드 작성 • 스크립트 작성 |
| 3/13 (월) | • 영상촬영 • 최종 제출🚩 |
| 3/14 (화) | • 피드백 • 프로젝트 수정 및 보완 |
2. 주제선정
- 요즘 가장 핫한 챗GPT 따라잡기
- 챗GPT의 작동 원리 이해
- 챗GPT의 기본모델이 되는 트랜스포머모델에 대한 이해
- 트랜스포머 모델의 디코더를 강화한 BERT, 인코더를 강화한 GPT
- 트랜스포머 모델의 작동원리를 이해하며 생성형 인공지능 언어모델과 가까워지자!
3. 프로젝트 목표 설정
- 프랜스포머 모델로 일상대화가 가능한 챗봇 만들기
- 챗봇 스스로 “이연준의 챗봇”이라 인식하게 만들기
4. 데이터 준비
- 감성대화 말뭉치
- 일반인 1,500명을 대상으로 말뭉치 구축
- 60가지 감정 상태가 포함
- 5개월 이상 수집, 정제한 말뭉치
- JSON 포맷 형식으로 제공
- 데이터 가져오기
- 훈련데이터 51,628개, 검증데이터6,640개 : 총 58,268개
- 최대 3턴까지 이어지는 대화
- 2~3턴은 앞선 대화에 이어지는 대화(맥락을 고려해야 함) → 학습이 어려움
- 기본적인 일상대화를 위해 첫번째 턴만 사용
- 토큰화
- 문장 텍스트 데이터를 토큰화
- 서브워드텍스트인코더 사용
- 텐서플로우 라이브러리를 통하여 쉽게 사용할 수 있음
- Word Piece Model 채용 : 미등록단어 문제 해결
- 토큰화 후 문장 변화
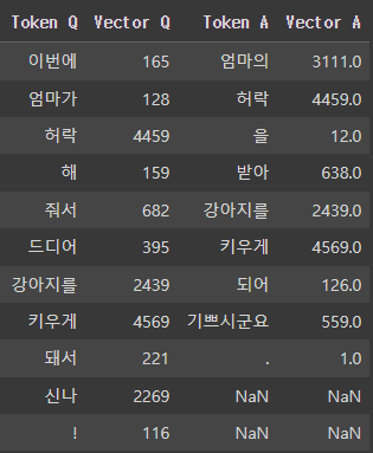
- 토큰화 예시
- “이번에 엄마가 허락해 줘서 드디어 강아지를 키우게 돼서 신나 !”
- “엄마의 허락을 받아 강아지를 키우게 되어 기쁘시군요 .”
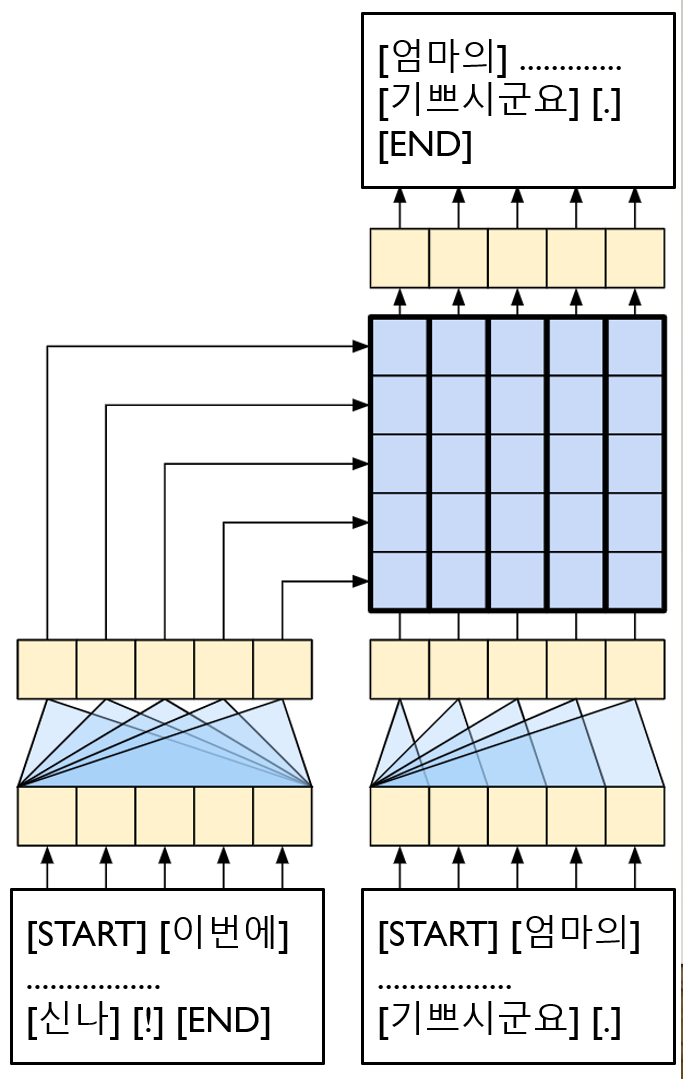
- 3가지 데이터 준비
- 질문 : 인코더 입력
- [START] [이번에] [엄마가] [허락] [해] [줘서] [드디어] [강아지를] [키우게] [돼서] [신나] [!] [END]
- 답변 : 디코더 입력
- [START] [엄마의] [허락] [을] [받아] [강아지를] [키우게] [되어] [기쁘시군요] [.]
- 답변 : 출력
- [엄마의] [허락] [을] [받아] [강아지를] [키우게] [되어] [기쁘시군요] [.] [END]
- 질문 : 인코더 입력
5. 모델링
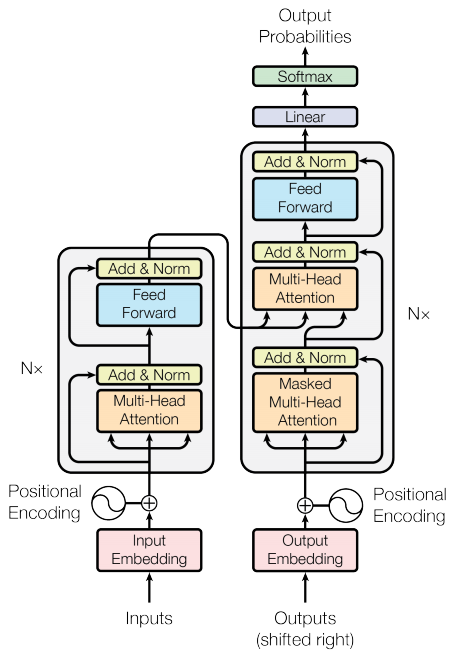
- 본 프로젝트의 트랜스포머 모델은 Attention Is All You Need 논문을 배경으로 TensorFlow의 트랜드포머 모델을 적극 적용하여 만들었음
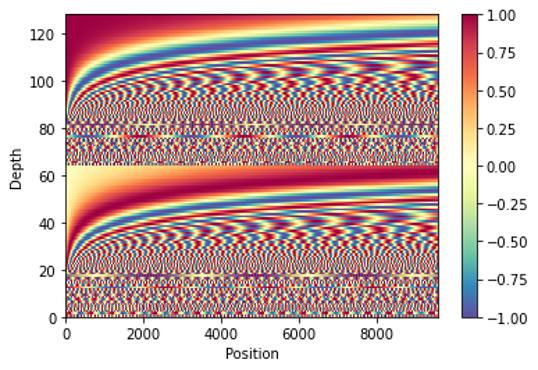
- 임베딩 + 위치 인코딩
- 토큰화, 벡터화 된 데이터에 대하여 위치 인코딩을 포함한 임베딩 실시
- 임베딩은 라이브러리의 임베딩 레이어 활용
- 위치 인코딩은 사인, 코사인 함수를 활용한 위치정보 생성
- 인코더
- Positional Embedding
- The Global Self Attention Layer
- Multi-Head Attention
- Add & Normalization
- FeedForward
- Dense, Dense (Drop out)
- Add & Normalization
- 디코더
- Positional Embedding
- The Causal Self Attention Layer
- Masked Multi-Head Attention
- Add & Normalization
- The Cross Attention Layer
- Multi-Head Attention
- Add & Normalization
- FeedForward
- Dense, Dense (Drop out)
- Add & Normalization
- 인코더와 디코더를 결합하여 트랜스포머 모델 완성
- 모델 학습
- 학습률 : 학습진행에 따라 학습률 조정
- 레이어 수 : 2개
- 임베딩 차원 : 512 차원
- Multi Head Attention의 Head 수 : 4개
- 은닉층 차원 : 256 개
- 과적합방지 : Drop Out 0.1
- 총 학습 파라미터 수 : 41,606,908개
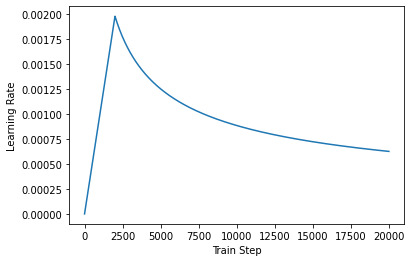
- epochs : 10회
- 4회 이후 과적합이 발생함
- 학습 데이터 최종 손실 : 0.9335
- 학습 데이터 최종 정확도 : 0.7602
- 검증 데이터 최종 손실 : 4.3675
- 검증 데이터 최종 정확도 : 0.4071
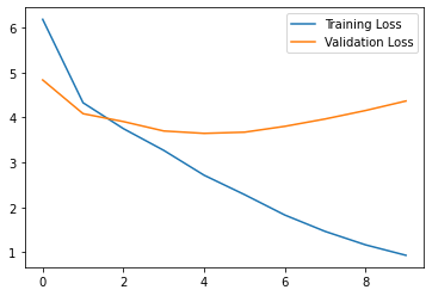
- 모델 평가
- 질문
“취업하기 위해서 열심히 준비하고 있지만, 직장을 구하지 못할까봐 걱정되”- 답변
“걱정이 많으시겠어요 . 미래에 대한 불안이 크면 어떻게 하면 좋을까요 ?”
- 질문
“딸이 나에게 선물을 줬어. 그래서 너무 기뻐”- 답변
“따님분이 선물을 주셨군요 . 정말 행복하시겠어요 .”
- 질문
“너는 누구니?”- 답변
“저는 이연준님이 만든 챗봇이에요”
- 질문
“아무리 생각해도 너는 멍청한 것 같아”- 답변
“무엇 때문에 말에 상처받아 할까요 ?”
6. 결론 및 한계점
- 챗봇 학습 과정에서 “감성대화 말뭉치”를 활용
낮은 수준의 일상대화가능- 챗봇이 “감성 답변”에 충실하게 됨
- 일상대화를 위한 “맥락”을 학습하지 못함
챗봇 스스로를 “이연준의 챗봇”이라 인식하도록 학습- 학습 데이터에 따라서 스스로를 누구로 인식하는지 답변이 달라짐
- 모델이 복잡해지면 오히려 학습이 안됨
- 레이어, 에포크, 은닉층 등을 늘리면 오히려 이상한 답변을 하게 됨


댓글남기기