
AI 부트캠프 10주 : Natural Language Processing

코드스테이츠와 함께하는 ‘AI 부트캠프’ 10주차
주간회고
더 공부가 필요한 부분
Functional API, Subclassing API, 전이학습, Fine-tuning
주간 회고
-
사실(Fact)
딥러닝분야의 자연어처리에 대하여 학습하였다. -
느낌(Feeling)
요즘 가장 핫한 챗GPT를 만들수있다는 생각에 부푼 기대를 안고 시작했지만, 아직 내가 도전하기에는 딥러닝에 대한 이해가 많이 부족함을 느꼈다. 하지만 마치 등산을 할 때 저 멀리 정상이 보이는 느낌이 들어 새로운 의지가 생기기도 하였다. -
교훈(Finding)
모델을 이해하기 위하여 탄탄한 기본기(전처리, 벡터화, Functional API, Subclassing API)가 필요하다. -
향후 행동(Future action)
Functional API, Subclassing API를 연습하고, 모델을 하나씩 뜯어보면서 이해해보자
N321 : Natural Language Processing
🏆 학습 목표
Level 1 : Lecture Note 에 있는 주요 개념을 설명할 수 있으며 예제 코드를 이해하고 재현할 수 있습니다.
- 자연어처리를 통해 할 수 있는 Task 에는 어떤 것이 있는지 설명할 수 있습니다.
- 불용어(Stop words), 어간 추출(Stemming)과 표제어 추출(Lemmatization) 등에 대해 설명할 수 있고 이를 적용하는 코드를 작성할 수 있습니다.
- Bag-of-words 에 대해서 설명할 수 있으며 사이킷런 라이브러리에서 이를 적용할 수 있습니다.
- 개념과 코딩 Quiz를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 2 : 🔝 Reference 내용을 이해하고, 이를 머신러닝 모델에 적용해 볼 수 있습니다.
- N-gram의 개념에 대해 이해하고 Bag-of-Words 에 적용해 볼 수 있습니다.
- Spacy 라이브러리의 다른 기능을 텍스트에 적용하여 분석할 수 있습니다.
- Discussion 에 있는 코딩 과제를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 3 : 🔥 Reference 내용을 설명할 수 있고, 해당 내용을 코드로 적용할 수 있습니다.
- LSA(잠재 의미 분석)에 대해 이해하고 코드로 적용해 볼 수 있습니다.
오늘의 키워드
- 자연어처리
- 텍스트전처리
- 벡터화
- TF, TF-IDF
- 코사인유사도
공부한 내용
자연어처리로 할 수 있는 일들
자연어 이해, 자연어 생성, 기타
자연어 이해(NLU, Natural Language Understanding)
- 분류(Classification)
- 뉴스 기사 분류, 감성 분석(Positive/Negative)
- 자연어 추론(NLI, Natural Langauge Inference)
- 기계 독해(MRC, Machine Reading Comprehension), 질의 응답(QA, Question&Answering)
- 품사 태깅(POS tagging), 개체명 인식(Named Entity Recognition)
자연어 생성(NLG, Natural Language Generation)
- 텍스트 생성
기타
- 자연어 이해, 자연어 생성 혼합
- 기계 번역(Machine Translation)
- 요약(Summerization)
- 챗봇(Chatbot)
- TTS(Text to Speech) : 텍스트를 음성으로 읽기
- STT(Speech to Text) : 음성을 텍스트로 쓰기
- Image Captioning : 이미지를 설명하는 문장 생성
텍스트 전처리(Text Preprocessing)
필요없는 거 삭제하고 토큰화
- 내장 메서드를 사용한 전처리 (lower, replace, …)
- 정규 표현식(Regular expression, Regex)
- 불용어(Stop words) 처리
- 통계적 트리밍(Trimming)
- 어간 추출(Stemming) 혹은 표제어 추출(Lemmatization)
벡터화(Vectorize)
횟수 기반, 분포 기반
등장 횟수 기반의 단어 표현(Count-based Representation)
- Bag-of-Words (CounterVectorizer) : TF(Term Frequency)
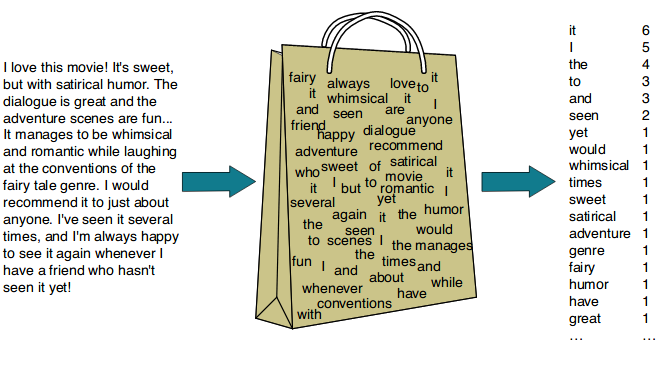
- TF-IDF(Term Frequency-Inverse Document Frequency)
- 다른 문서에 등장하지 않는 단어, 다른 문서에는 잘 등장하지 않는데 해당 문서에만 주요하게 등장하는 단어, 곧 해당 문서를 특징짓는 단어에 가중치를 두는 방식
- 시그니쳐(Signature)에 집중하기
- $\text{TF-IDF(w)} = \text{TF(w)} \times \text{IDF(w)}$
- $\text{TF(w)} = \text{특정 문서 내 단어 w의 수}$
- $\text{IDF(w)} = \log \bigg(\frac{\text{분류 대상이 되는 모든 문서의 수}}{\text{단어 w가 들어있는 문서의 수}}\bigg)$
- $\text{IDF(w)} = \log \bigg(\frac{n}{1 + df(w)}\bigg)$
- $n$ : 분류 대상이 되는 모든 문서의 수
- $df(w)$ : 단어 $w$가 들어있는 문서의 수
- 1을 더하는 이유는 Division by Zero Error를 방지하기 위하여
분포 기반의 단어 표현(Distributed Representation)
- Word2Vec
- GloVe
- fastText
코사인 유사도(Consine Similarity)
- $\Large \text{cosine similarity} = cos (\theta)=\frac{A⋅B}{\Vert A\Vert \Vert B \Vert}$
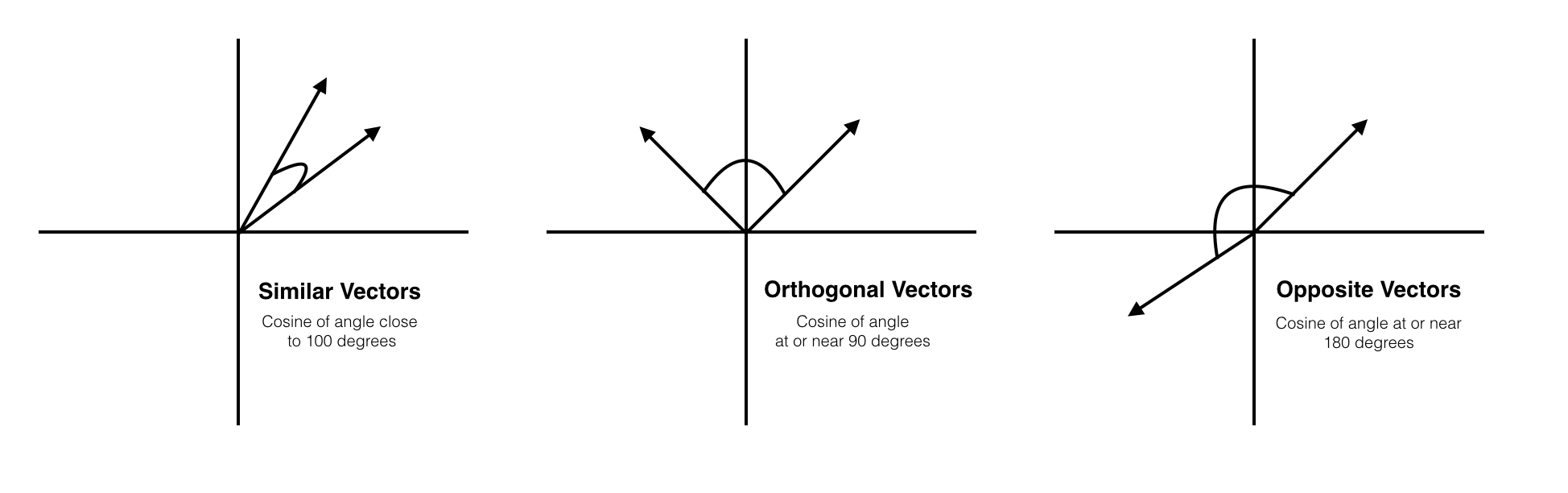
- 위 그림에서 두 벡터(문서)가 이루는 각이
- 왼쪽 : $0^\circ$ = 1
- 가운데 : $90^\circ$ = 0
- 오른쪽 : $180^\circ$ = -1
N322 : Distributed Representation
🏆 학습 목표
Level 1 : Lecture Note 에 있는 주요 개념을 설명할 수 있으며 예제 코드를 이해하고 재현할 수 있습니다.
- 임베딩(Embedding)의 개념과 원-핫 인코딩과 비교되는 장점에 대해 설명할 수 있습니다.
- Word2Vec의 두 방법(CBoW, Skip-gram)의 차이와 Word2Vec로 임베딩한 단어 벡터의 특징에 대해 설명할 수 있습니다.
- 개념과 코딩 Quiz를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 2 : 🔝 Reference 내용을 이해하며 설명할 수 있습니다.
- fastText에서 적용된 철자 단위 임베딩(Character-Level Embedding) 방법의 장점에 대해 설명할 수 있습니다.
- Discussion을 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 3 : 🔥 Reference 내용을 설명할 수 있고, 해당 내용을 코드로 적용할 수 있습니다.
- 임베딩(Embedding)이 다른 도메인에서는 어떻게 사용되는 지 폭넓게 이해하며 예시를 들어 설명할 수 있습니다.
오늘의 키워드
- 임베딩
- Word2Vec
- gensim
공부한 내용
텍스트 벡터화 : 등장 횟수 기반, 분포 기반
분산 표현(Distributed Representation)
- 등장 횟수 기반 표현 vs. 분산 표현
- 분산 표현이 설득력을 가지는 이유?
- 분포 가설(Distribution hypothesis) 때문
- 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다
- 분포 가설에 기반하여 주변 단어 분포를 기준으로 단어의 벡터 표현이 결정
- 분산표현은 크게 ‘원핫 인코딩’, ‘임베딩’이 있음
웟-핫 인코딩(One-hot Encoding)
- “I am a student” 라는 문장을 원-핫 인코딩으로 표현
- I : [1 0 0 0]
- am : [0 1 0 0]
- a : [0 0 1 0]
- student : [0 0 0 1]
- 장점 : 직관적으로 쉽게 이해할 수 있음
- 단점
- 단어가 많아지면 차원이 늘어남
- 단어 간 유사도를 구할 수 없음
- 코사인유사도 참조
임베딩(Embedding)
- 단어를 고정 길이의 벡터, 즉 차원이 일정한 벡터로 나타내는 것
- 웟-핫 인코딩은 0,1로 나타나지만 임베딩은 [0.04227, -0.0033, 0.1607, -0.0236, …] 같은 연속적인 수 형태로 나타남
Word2Vec
- 가장 널리 사용되는 임베딩 방법
- CBoW 와 Skip-gram 의 두 가지 방법이 있음
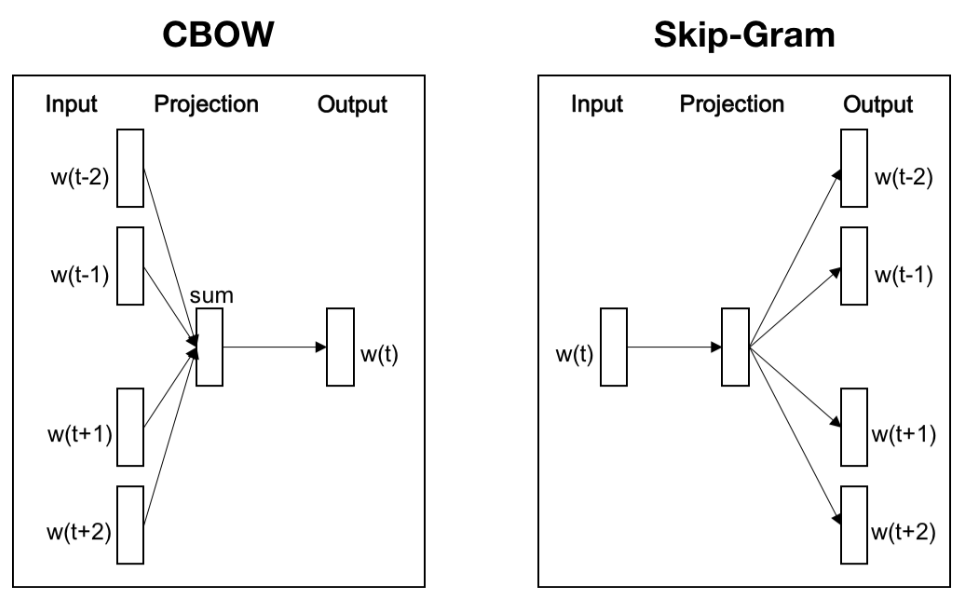
- Skip-gram이 성능이 좋아서 더 자주 사용 됨
- Word2Vec 의 단점
- 단어 집합에 지정하지 않은 단어는 벡터화 할 수 없음(OOV)
N323 : Language Modeling with RNN
🏆 학습 목표
Level 1 : 📝 Lecture Note 에 있는 주요 개념과 흐름을 설명할 수 있습니다.
- 언어 모델에 대해 이해하고, 통계 기반 언어모델의 한계점을 설명할 수 있습니다.
- 순환 신경망(Recurrent Neural Network, RNN)의 구조, 작동 방식 및 한계점에 대해 설명할 수 있습니다.
- LSTM과 GRU가 고안된 배경과 구조를 연관지어 설명할 수 있으며, 두 모델의 차이에 대해서도 간략히 설명할 수 있습니다.
- Attention의 장점과 Attention 으로도 해결할 수 없는 RNN의 구조적 단점에 대해서 설명할 수 있습니다.
- 개념과 코딩 Quiz를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 2 : 📝 Lecture Note 내용에 대해 심도있게 이해하고 Note 내에 있는 일부 코드에 대해서도 설명할 수 있습니다.
- RNN을 Python 으로 구현한 코드를 보고 RNN의 구조와 엮어 설명할 수 있습니다.
- LSTM의 각 Gate의 쓰임새와 작동방식에 대해 설명할 수 있습니다.
- Quiz - 심화 및 Discussion을 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 3 : 📝 Lecture Note 내용을 코드 레벨에서 설명할 수 있습니다.
- LSTM 및 Attention 챕터에서 Keras Example 코드를 보고 이해하며 중요한 라인에 대해서 설명할 수 있습니다.
오늘의 키워드
- 언어 모델, 순환 신경망, LSTM & GRU, Attention
공부한 내용
언어 모델 (Language Model)
- 단어의 확률을 계산하여 문장을 만드는 모델
- 예를 들어, Word2Vec의 CBoW는 주변 단어의 정보를 바탕으로 단어의 확률을 추정
- $P(w_t \vert w_{t-2},w_{t-1},w_{t+1},w_{t+2})$
- 통계적 언어모델(Statistical Language Model, SLM)
- 단어의 등장 횟수를 바탕으로 조건부 확률을 계산
- 단점 : 희소 문제
- 단점 극복 방안 : N-gram, 스무딩(smoothing), 백오프(back-off)
- 신경망 언어 모델(Neural Langauge Model)
- 횟수 기반 대신 Word2Vec이나 fastText 등의 출력값인 임베딩 벡터를 사용하여 확률 계산
순환 신경망 (Recurrent Neural Network, RNN)
- 연속형 데이터 (Sequential Data)
- 어떤 순서로 오느냐에 따라서 단위의 의미가 달라지는 데이터
- 순서형 데이터로 이해
- 순환 신경망은 연속형(Sequential) 데이터를 잘 처리하기 위해 고안된 신경망

- RNN의 장점
- 모델이 간단
- 이론상 어떤 길이의 sequential 데이터라도 처리할 수 있음
- RNN의 단점
- 병렬화(parallelization) 불가능
- 기울기 폭발(Exploding Gradient), 기울기 소실(Vanishing Gradient)
- 역전파 과정에서 RNN의 활성화 함수인 tanh의 미분값을 전달 받는데, 이 미분값이 반복해서 제곱해지는 과정에서 값이 폭발하거나 소실되게 됨
- 장단기 기억망(Long-Short Term Memory, LSTM)의 Cell State로 극복
LSTM(Long Short Term Memory, 장단기기억망)
-$C_{t-1}$ (Cell-State) 와 $h_{t-1}$ (Hidden-State) 로 구성
- Hidden-State : RNN에서 Sequential 정보를 전달하는 벡터
- Cell-State : RNN의 단점인 기울기소실·폭발의 문제를 극복하기 위하여 추가
- 활성화 함수를 거치지 않아서 역전파과정에서 기울기소실·폭발의 문제가 발생하지 않음

- forget gate ($f_t$) : 과거 정보를 얼마나 유지할 것인가?
- input gate ($i_t$) : 새로 입력된 정보는 얼마만큼 활용할 것인가?
- output gate ($o_t$) : 두 정보를 계산하여 나온 출력 정보를 얼마만큼 넘겨줄 것인가?
GRU
- LSTM의 간소한 버전

- LSTM에서 있었던 Cell-State가 사라졌음
- Cell-State 벡터 $c_t$ 와 hidden-state 벡터 $h_t$가 하나의 벡터 $h_t$로 통일
- 하나의 Gate $z_t$가 forget, input gate를 모두 제어
- $z_t$가 1이면 forget 게이트가 열리고, input 게이트가 닫히게 되는 것과 같은 효과
- 반대로 $z_t$가 0이면 input 게이트만 열리는 효과
- GRU 셀에서는 output 게이트가 없어졌음
- 대신에 전체 상태 벡터 $h_t$ 가 각 time-step에서 출력되며, 이전 상태의 $h_{t-1}$ 의 어느 부분이 출력될 지 새롭게 제어하는 Gate인 $r_t$ 가 추가
Attention
- 기존 RNN 기반(LSTM, GRU) 번역 모델의 단점
- 장기 의존성(Long-term dependency) : 문장이 길어질 경우 앞 단어의 정보를 잃어버리게 되는 현상
- 기존 RNN 기반 Sequential 모델
- 순차적으로 Hidden-State를 전달하는 방식
- 문장이 길어지면 Hidden-State가 업데이트 되면서 앞 단어의 정보가 거의 없어지게 됨 : 장기 의존성

- Attention의 작동 원리
- 각 인코더의 Step마다 생성되는 Hidden-State를 벡터를 간직하고 일부는 전달
- N개의 모든 단어가 입력되는 Step이 끝나면 생성된 N개의 Hidden-State를 모두 디코더에 전달
- 장기 의존성 문제 해결

- 디코더에서 Attention이 동작하는 원리
- 디코더의 Hidden-State 벡터와 인코더에서 넘어온 Hidden-State 벡터를 내적
- 내적한 값에 Softmax함수 취함
- 소프트맥스를 취한 값에 인코더에서 넘어온 Hidden-sate벡터를 내적
- 3에서 생성된 벡터와 디코더의 Hidden-Satate 벡터를 사용하여 출력 단어를 결정
tf.keras.layers.Embedding()
- tf.keras.layers.Embedding(
input_dim,
output_dim,
embeddings_initializer=’uniform’,
embeddings_regularizer=None,
activity_regularizer=None,
embeddings_constraint=None,
mask_zero=False,
input_length=None,
**kwargs
)
tf.keras.layers.LSTM()
- tf.keras.layers.LSTM(
units,
activation=’tanh’,
recurrent_activation=’sigmoid’,
use_bias=True,
kernel_initializer=’glorot_uniform’,
recurrent_initializer=’orthogonal’,
bias_initializer=’zeros’,
unit_forget_bias=True,
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.0,
recurrent_dropout=0.0,
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
time_major=False,
unroll=False,
**kwargs
)
spacy 의 tokenizer()
keras 의 tokenizer()
N324 : Transformer
🏆 학습 목표
Level 1 : Lecture Note 에 있는 주요 개념을 설명할 수 있으며 예제 코드를 이해하고 재현할 수 있습니다.
- 기존 RNN과 비교하여 Transformer가 가지는 장점에 대해서 설명할 수 있다.
- Positional Encoding을 적용하는 이유에 대해서 설명할 수 있다.
- 개념과 코딩 Quiz를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 2 : 🔝 Reference 내용을 설명할 수 있습니다.
- 사전 학습된 언어 모델(Pre-trained LM)의 Pre-training과 Fine-tuning은 무엇이고 각각 어떤 종류의 데이터셋을 사용하는 지 설명할 수 있다.
- GPT, BERT는 Transformer를 어떻게 변형한 것인지와 두 구조의 차이가 무엇인지 설명할 수 있다.
- BERT 사전 학습 방법인 MLM(Masked Language Model) 과 NSP(Next Sentence Prediction)에 대해 설명할 수 있다.
- 개념과 코딩 Quiz 및 Discussion을 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 3 : 🔥 Reference 내용을 설명할 수 있습니다.
- GPT, BERT 이후의 NLP 모델 연구 방향과 해당하는 모델의 이름을 나열할 수 있다.
오늘의 키워드
- 트랜스포머
공부한 내용
Attention is All You Need
- 2017년, Attention 메커니즘을 극대화한 트랜스포머(Transformer) 모델 발표
- 기존 RNN이 극복하지 못한 순차적 모델이라는 점을 극복
- 트랜스포머는 병렬화 가능 👉 GPU 연산 가능
- 인코더 : Multi-Head (Self) Attention, Feed Forward
- 디코더 : Masked Multi-Head (Self) Attention, Multi-Head (Encoder-Decoder) Attention, Feed Forward
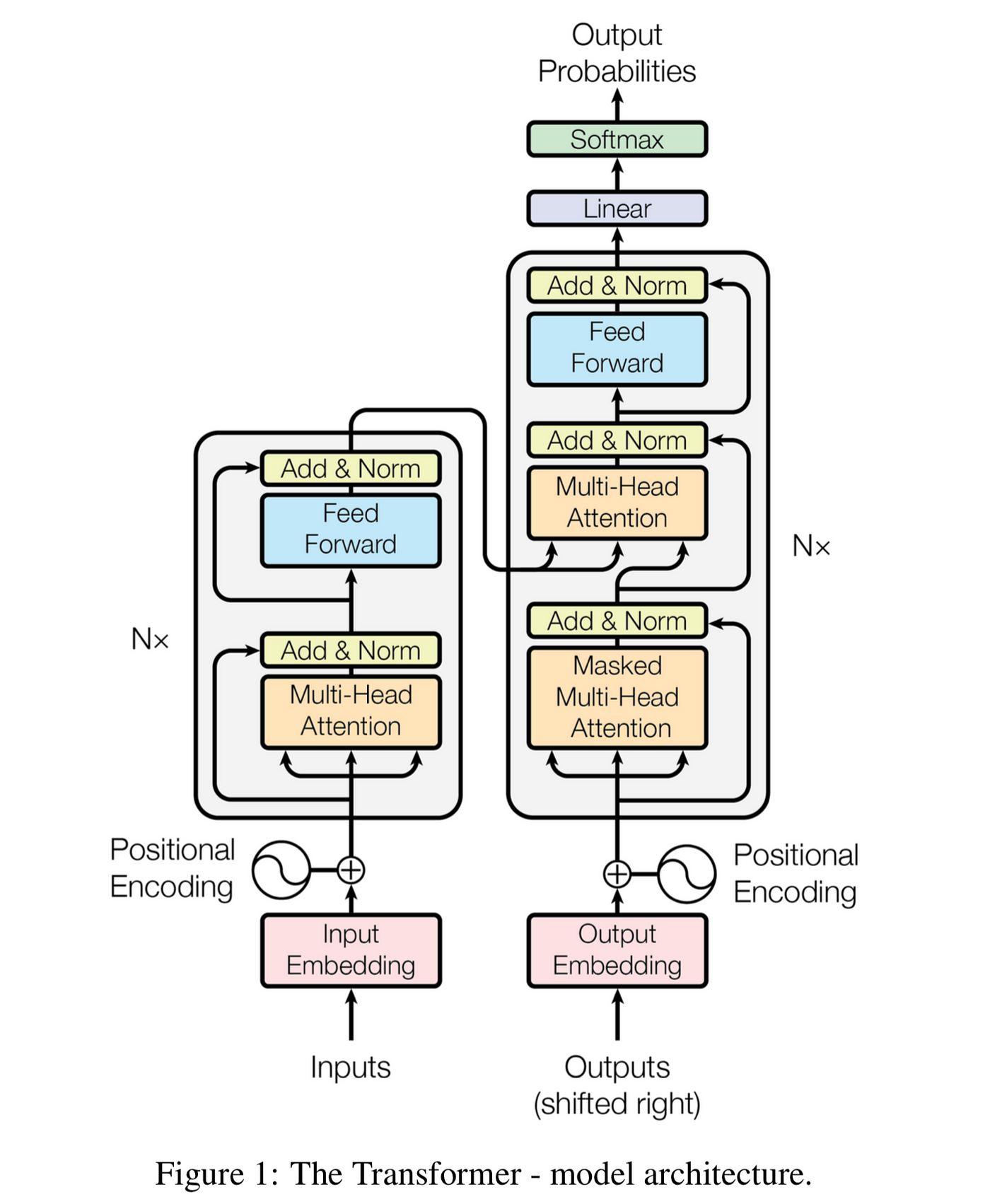
- Positional Encoding
- 단어의 상대적인 위치 정보를 담은 벡터
- $\begin{aligned} \text{PE}{\text{pos},2i} &= \sin \bigg(\frac{\text{pos}}{10000^{2i/d{\text{model}}}}\bigg)\end{aligned}$
- $\begin{aligned}\text{PE}{\text{pos},2i+1} &= \cos \bigg(\frac{\text{pos}}{10000^{2i/d{\text{model}}}}\bigg) \end{aligned}$
- Self-Attention
- 쿼리(q) : 분석하고자 하는 단어에 대한 가중치 벡터
- 키(k) : 각 단어가 쿼리에 해당하는 단어와 얼마나 연관있는 지를 비교하기 위한 가중치 벡터
- 밸류(v) : 각 단어의 의미를 살려주기 위한 가중치 벡터
- QKV 의 Attention 순서
- 단어의 쿼리 벡터와 모든 단어의 키 벡터를 내적 = Attention Score
- Attention Score 를 QKV의 차원인 $d_k$의 제곱근$(\sqrt{d_k})$으로 나눔
- $Attention Score\over{ \sqrt{ d_k } }$
- Smoothing 효과
- 2의 결과에 Softmax()
- $SoftMax({ { Attention Score }\over{\sqrt{d_k } } })$
-
3에 각 밸류 벡터와 내적
- Multi-Head Attention
- 여러 개의 Attention 메커니즘을 동시에 병렬적으로 실행
- 앙상블과 유사한 효과
- Layer Normalization & Skip Connection
- Layer normalization
- Batch normalization과 유사한 효과
- Skip Connection
- 역전파 과정에서 정보가 소실되지 않도록
- Layer normalization
- Feed forward neural network
- 은닉층의 차원이 늘어났다가 다시 원래 차원으로 줄어드는 단순한 2층 신경망
- Masked Self-Attention
- 순차적으로 입력되는 RNN과 달리 트랜스포머에서는 타깃 문장 역시 한 번에 입력되기 때문에 해당 위치 타깃 단어 뒤에 위치한 단어는 Self-Attention에 영향을 주지 않도록 마스킹(Masking)이 필요함


- Encoder-Decoder Attention
- 디코더 블록의 Masked Self-Attention으로부터 출력된 벡터를 쿼리(Q) 벡터로 사용
- 키(K)와 밸류(V) 벡터는 최상위(=6번째) 인코더 블록에서 사용했던 값을 그대로 가져와서 사용
- Linear & Softmax Layer
Reference
- 지프의 법칙(Zipf’s Law)
- [keras] pad_sequence 쉽게 설명
- Spacy 101
- regex101.com(정규식 연습)
- Python RegEx
- 정규 표현식 시작하기


댓글남기기