
AI 부트캠프 13주

코드스테이츠와 함께하는 ‘AI 부트캠프’ 13주차
S4-Week1 : 환경과 관계형 데이터베이스
주간회고
더 공부가 필요한 부분
데코레이터 만들기, 각종 API 활용, 데이터베이스 복제와 파티션
5F 회고
-
사실(Fact)
데이터 엔지니어링을 위한 파이썬 사용법, 웹스크래핑, API 사용법, NoSQL에 대하여 학습하였다. -
느낌(Feeling)
이미 홈페이지를 배포해본 경험이 있어서 익숙한 부분이 많았지만, 그동안 잘못알고 있던 것을 수정하고, 비어있는 부분은 보충하면서 더욱 단단해진 느낌이다. -
교훈(Finding)
어떤 내용을 알았다고해서 배움을 멈추지 말고 꾸준하게 공부하고, 다른 사람들의 코드를 참조하면서 꾸준하게 발전해나가야겠다. -
향후 행동(Future action)
파이써닉한 개발자가 되기 위하여 좋은 방법이 무엇인지 찾아보고, 아직 학습이 부족한 부분(데코레이터 만들기, 각종 API 활용, 데이터베이스 복제와 파티션)을 보충할 것이다. -
피드백(Feedback)
피드백을 해 주세요😀
N411 : Note 01 : 개발 환경
🏆ㅤ 학습 목표
🌱 Level 1 : Lecture Note 에 있는 주요 개념을 정의할 수 있으며 예제 코드를 이해하고 재현할 수 있다.
- 터미널을 이용하여 CLI에 접근하고, 노트에 기재된 TOP 5 기본 명령어를 이용한 작업들을 수행할 수 있다.
- 파이썬 가상환경이 왜 필요한지 설명할 수 있고, conda 예제를 재현할 수 있다.
- Git과 Github를 분류하여 설명할 수 있으며, 깃을 이용하여 버전 관리를 할 수 있다.
🔝 Level 2 : 예제 코드를 해석하고 응용할 수 있으며 과제를 수행할 수 있다.
- 워킹 디렉토리(작업 폴더)와 git, 가상환경을 분리해서 설명할 수 있다.
- conda를 이용하여 의도하는 가상환경을 생성 및 삭제할 수 있고, 코드를 해석하여 설명할 수 있다.
- requirements.txt 의 필요성을 설명할 수 있고, 제작할 수 있다.
- 코드의 변경 사항을 Git을 이용하여 기록하고 원격 레포에 반영하여 PR을 생성할 수 있다.
🔥 Level 3 : Lecture Note 에 있는 주요 개념과 코드를 연결하여 설명할 수 있으며 도전 과제를 수행할 수 있다.
- 기본 터미널 명령어를 찾아보지 않고 사용할 수 있다.
- conda 외의 파이썬 가상환경을 이용하여 의도하는 개발환경을 구축할 수 있다.
- Git branch를 이용할 수 있고, git pull 혹은 git merge 과정에서 발생하는 충돌을 해결할 수 있다.
🚀 Level 4 : Lecture Note 에 있는 개념 중 자신이 모르는 것을 구분해 낼 수 있으며 스스로 목표를 세우고 추가 학습을 진행할 수 있다.
- CLI, 터미널, 쉘을 분리해서 설명할 수 있다.
- 리눅스 역사와 철학을 설명할 수 있고, 우분투 리눅스 환경에서 파일 권한 설정을 할 수 있다.
- Git의 기본요소를 구성하는 스냅샷을 설명할 수 있다.
오늘의 키워드
- CLI, 가상환경, 아나콘다, Git, Github
공부한 내용
CLI
- 기본 명령어
# 현재 폴더의 경로 나타내기 pwd # 폴더 만들기 mkdir {폴더명} # 위치 이동 cd {폴더명} # Anaconda Powershell Prompt # 작업폴더로 이동 cd D:\coding\aib\Section4 # Gitbash # 작업폴더로 이동 cd /D/coding/aib/Section4 # 한단계 위로 이동 cd .. # 현재 디렉토리 안의 파일 및 폴더 목록을 출력 ls ls -l # 상세정보 출력 ls -a # 숨긴 파일까지 표시 ls -al # 숨긴 파일까지 상세정보 포함해서 출력
가상환경
- 파이썬에서 가상환경을 사용하는 이유?
- 파이썬 패키지는 하나의 버전만 설치할 수 있음
- 어플리케이션마다 다른 버전의 패키지가 필요할 수 있음
- 패키지 충돌을 방지하기 위하여 가상환경을 사용
- 정리하면, 하나의 어플리케이션에 최적화 된 파이썬 가상환경을 사용하면 패키지 충돌이 최소화 됨
- 가상환경 관리 툴
- 아나콘다
- 데이터과학분야에서 자주 사용됨
- 파이썬 버전지정 가능
- pipenv (공식문서, pipenv 사용법1, pipenv 사용법2)
- 파이썬 공식 가상환경 관리 툴
- 파이썬 버전지정 불가능
- venv
- Python 3.5 이후 파이썬 표준 라이브러리에 포함
- PyCharm에서 기본적으로 제공하는 가상환경
- virtualenv (공식문서, )
- 파이썬 버전지정 불가능
- pyenv (공식문서)
- 파이썬 버전지정 가능
- 아나콘다
아나콘다
- 기본 명령어
# 버전 확인 conda --version # 가상환경 리스트 보기 conda env list conda info --envs # 가상환경 생성 conda create --name 'practice' python=3.8 # 설치 기본경로 C:\Users\leeyeonjun85\.conda\envs # 경로 설정해서 가상환경 만들기 conda create --prefix 'C:/coding/practice' python=3.8 # 가상환경 삭제 conda env remove --name 'practice' conda remove --name 'practice' --all # 가상환경 실행 conda activate 'practice' # Git bash 에서 가상환경 실행 source C:/ProgramData/Anaconda3/Scripts/activate {가상환경이름} # 가상환경 종료 conda deactivate # TEXT파일에서 가상환경에 패키지 설치 pip install -r requirements.txt # 가상환경 패키지를 TEXT파일로 생성 pip freeze > requirements.txt # 파이썬 가상환경에서 주피터노트북 실행을 위한 라이브러리 pip install ipykernel
Git & Github
# Git 원격레포 등록
git remote add {원격 저장소 이름} {원격 저장소 주소}
# 깃repo 클론
git clone {git repo 주소 ~~.git}
git clone {git repo 주소 ~~.git} {D:/coding/aib/Section4/폴더이름}
# 클론한 폴더를 VSCode로 실행
code {D:/coding/aib/폴더이름}
# 변경 파일 확인
git status
# 변경 파일 추가하기
git add .
# 변경파일 취소하기
git reset HEAD^
# 커밋 진행
git commit -m "1차 제출"
# 원격저장소 이름 보기
git remote -v
# push
git push
# Add , Commit , Push 를 한번에
git add . && git commit -m "Update" && git push
과제관련
# 패키지 설치(requirements.txt에서 pytest 설치 후 실행 할 것)
# 과제관련 패키지가 설치되었는지 확인하기
pip list | findstr pytest
# 파이테스트 점검
python -m pytest tests
# 파이테스트 점검 : tests/Part_1 를 점검
python -m pytest tests/Part_1
# 제출하기
python -m pytest --submit
# 점수 확인
python -m pytest --score
python -m pytest --all # 제출한 모든 과제 점수 확인
python -m pytest --all 5 # Section 4 에 제출한 모든 과제 점수를 확인
N412 : Note 02 : SQL (01)
🏆ㅤ 학습 목표
- 🌱 Level 1 : Lecture Note 에 있는 주요 개념을 정의할 수 있으며 예제 코드를 이해하고 재현할 수 있다.
- 데이터베이스의 필요성과 관계형 데이터베이스의 특징을 설명할 수 있다.
- SQL 특징을 설명할 수 있고, 스키마를 통해 관계를 설명할 수 있다.
- SQL Basics를 이해하고 예제를 재현할 수 있다.
- 🔝 Level 2 : 예제 코드를 해석하고 응용할 수 있으며 과제를 수행할 수 있다.
- 주어진 스키마를 SQL을 활용하여 구현할 수 있다.
- SQL 쿼리문을 활용하여 원하는 조건의 데이터를 출력할 수 있다.
- 🔥 Level 3 : Lecture Note 에 있는 주요 개념과 코드를 연결하여 설명할 수 있으며 도전 과제를 수행할 수 있다.
- 주어진 데이터와 출력값을 살펴보고 어떤 SQL 쿼리문을 사용할지 판단하고 구현할 수 있다.
- SQL JOIN 의 종류를 분류하고 활용 예시를 들어 설명할 수 있다.
- 🚀 Level 4 : Lecture Note 에 있는 개념 중 자신이 모르는 것을 구분해 낼 수 있으며 스스로 목표를 세우고 추가 학습을 진행할 수 있다.
- 3층 스키마에 대해 데이터베이스를 보는 관점과 연관지어 간단하게 설명할 수 있다.
- 함수 종속과 정규화(제3정규형까지)를 연관지어 설명할 수 있고, 정규화가 필요한 이유에 대해 설명할 수 있다.
오늘의 키워드
- 데이터베이스, 관계형 데이터베이스, SQL, 쿼리문, JOIN
공부한 내용
데이터베이스(database, DB)
- 데이터의 집합
관계형 데이터베이스(Relational Database)
- 키(key)와 값(value)들의 간단한 관계를 테이블화 시킨 데이터베이스

SQL(Structured Query Language)
- 관계형 데이터베이스를 관리하기 위한 프로그래밍 언어
SQL 쿼리문
- SQL의 JOIN 종류

3층 스키마
- 사용자(외부스키마), 설계자(개념스키마), 개발자(내부스키마)가 데이터 베이스를 보는 관점에 다라 데이터 베이스를 기술하고 이들간의 관계를 정의한 ANSI 표준
- 데이터베이스의 독립성을 확보하기 위한 방법임
- 독립성을 확보하면 생기는 장점
- 데이터 복잡도 증가
- 데이터 중복 제거
- 사용자 요구사항 변경에 따른 대응력 향상
- 관리 및 유지보수 비용 절감
- 각 계층을 view 라고도 함

| 구조 | 설명 |
|---|---|
| 외부 스키마 (External Schema) |
• 사용자 관점 • 업무상 관련이 있는 데이터 접근 • 관련 데이터베이스의 뷰(View)를 표시 • 응용 프로그램이 접근하는 데이터베이스를 정의 |
| 개념 스키마 (Conceptual Schema) |
• 설계자 관점 • 사용자 전체 집단의 데이터베이스 구조 • 전체 데이터베이스 내의 규칙과 구조를 표현 • 통합 데이터베이스 구조 |
| 내부 스키마 (Internal Schema) |
• 개발자 관점 • 데이터베이스의 물리적 저장 구조 • 데이터 저장 구조, 레코드 구조, 필드 정의, 인덱스 등을 의미 |
함수 종속성
- 함수 종속성(Functional Dependency)은 어떤 테이블의 속성 A와 B에 대하여, A값에 의해 B값이 유일하게 정해지는 관계를 말하며, “B는 A에 함수 종속이다”라고함
- A→B의 기호로 나타냄
- 이때, A를 결정자(Determinant)라고 하고, B를 종속자(Dependant)라고 함
- 완전 함수 종속 : 기본키를 구성하는 모든 속성에 종속되는 경우
- 부분 함수 종속 : 기본키를 구성하는 속성의 일부에 종속되거나, 기본키가 아닌 다른 속성에 종속되는 경우
- 이행적 함수 종속 : A, B, C 세 속성이 있고 A→B, B→C 종속 관계가 있을 때, A→C가 성립하는 경우

- 위 그림에서, 학년과 이름은 (학번, 과목번호)에 대해 부분 함수 종속이고, 성적은 완전 함수 종속
이상현상
- 이상현상이란, 테이블 내의 데이터들이 불필요하게 중복되어 테이블을 조작할 때 발생되는 데이터 불일치 현상을 말함
- 삽입 이상 (insertion anomaly) : 원하지 않는 자료가 삽입된다든지, key가 없어 삽입하지 못하는(불필요한 데이터를 추가해야 삽입할 수 있음) 문제점
- 삭제 이상 (deletion anomaly) : 하나의 자료만 삭제하고 싶지만, 그 자료가 포함된 튜플 전체가 삭제됨으로 원하지 않는 정보 손실이 발생하는 문제점
- 갱신 이상 (update anomaly) : 일부만 변경하여 데이터가 불일치하는 모순, 또는 중복되는 튜플이 존재하게 되는 문제점
정규화
- 정규화 과정이란, 이상 현상을 해결하기 위한 과정
- 정규화 3원칙
- 정보의 무손실 : 분해된 릴레이션이 표현하는 정보는 분해되기 전의 정보를 모두 포함해야 한다.
- 최소 데이터 중복 : 이상 현상을 제거, 데이터 중복을 최소화
- 분리의 원칙 : 하나의 독립된 관계성은 하나의 독립된 릴레이션으로 분리해서 표현
- 시스템의 성능 향상을 위해 의도적으로 정규화 원칙을 위배하여 모델을 통합하는 반정규화(De-normalization)도 있음
정규형
- 정규형은 정규화된 결과를 의미
- 제1 정규형, 제2 정규형, 제3 정규형, BCNF, 제4 정규형, 제5 정규형이 있음
- 제1 정규형 (1NF)
- 릴레이션에 속하는 속성의 속성 값이 모두 원자값(Atomic Value)만으로 구성
- 제2 정규형 (2NF)
- 제1 정규형이면서, 기본키(primary key)에 속하지 않은 속성 모두가 기본키에 완전 함수 종속인 정규형
- 제3 정규형 (3NF)
- 제2 정규형이면서, 이행적 함수 종속성을 제거한 정규형
- BCNF
- BCNF (Boyce and Codd Normal Form)은 제3 정규형을 조금 더 강화시킨 개념
- 제4,5 정규형은 실무에서 잘 사용 안된다고 하니깐 생략!😉
N413 : Note 03 : SQL (02)
🏆ㅤ 학습 목표
🌱 Level 1 : Lecture Note 에 있는 주요 개념을 정의할 수 있으며 예제 코드를 이해하고 재현할 수 있다.
- 트랜잭션에 대해서 설명할 수 있고, COMMIT 과 Rollback 예제를 재현할 수 있다.
- ACID의 특징에 대해서 각각 설명할 수 있다.
- SQL 내장함수와 서브쿼리에 대해서 설명할 수 있다.
🔝 Level 2 : 예제 코드를 해석하고 응용할 수 있으며 과제를 수행할 수 있다.
- SQL 내장 함수와 CASE문을 활용하여 SQL 다중 테이블 쿼리를 할 수 있다.
- SELECT 실행 순서에 대해 설명할 수 있다.
🔥 Level 3 : Lecture Note 에 있는 주요 개념과 코드를 연결하여 설명할 수 있으며 도전 과제를 수행할 수 있다.
- 서브쿼리를 활용하여 원하는 데이터를 쿼리 해올 수 있다.
- 서브쿼리를 포함한 SELECT 쿼리문의 실행 순서를 설명할 수 있다.
🚀 Level 4 : Lecture Note 에 있는 개념 중 자신이 모르는 것을 구분해 낼 수 있으며 스스로 목표를 세우고 추가 학습을 진행할 수 있다.
- 슈퍼 키, 후보 키, 기본 키, 대체 키, 외래 키에 대해서 설명할 수 있다.
- 데이터베이스의 옵티마이저의 종류와 그 특징에 대해 설명할 수 있다.
- 데이터베이스의 인덱스에 대해 간단하게 설명할 수 있다.
오늘의 키워드
- 트랜잭션, ACID
공부한 내용
트랜잭션
- 트랜잭션(transaction)
- 데이터베이스의 ACID이 보장되는 데이터베이스 작업의 기본 단위
- 쪼갤 수 없는 업무 처리의 최소 단위
- 데이터베이스의 상태를 변화시키는 작업의 모음
- commit으로 트랜잭션이 마무리 됨
- rollback 은 commit하기 전 작업을 취소
ACID
- 원자성 Atomicity
- 하나의 트랜잭션을 구성하는 작업들은 전부 성공하거나 전부 실패해야 되어야 한다는 것
- 일관성 Consistency
- 하나의 트랜잭션 이전과 이후 데이터베이스 상태는 이전과 같이 유효해야 한다는 것
- 각종 제약과 규칙에 따라야 한다는 것
- 고립성 Isolation
- 하나의 트랜잭션은 다른 트랜잭션과 독립되어야 한다는 것
- 지속성 Durability
- 하나의 트랜잭션이 성공적으로 수행되었다면 해당 트랜잭션에 대한 로그가 남고 런타임 오류나 시스템 오류가 발생해도 해당 기록은 영구적이어야 한다는 것
SELECT 문 실행 순서
- 예시 쿼리
SELECT CustomerId, AVG(Total) FROM invoices WHERE CustomerId >= 10 GROUP BY CustomerId HAVING SUM(Total) >= 30 ORDER BY 2FROM invoices: invoices 테이블에 접근WHERE CustomerId >= 10: ‘CustomerId’ 필드가 10 이상인 레코드들을 조회GROUP BY CustomerId: ‘CustomerId’ 를 기준으로 그룹화HAVING SUM(Total) >= 30: ‘Total’ 필드의 값들의 합이 30 이상인 결과들만 필터SELECT CustomerId, AVG(Total): 조회된 결과에서 ‘CustomerId’ 필드와 ‘Total’ 필드의 평균값을 가져옴ORDER BY 2: AVG(Total) 필드를 기준으로 오름차순 정렬
슈퍼 키, 후보 키, 기본 키, 대체 키, 외래 키
- 슈퍼키(Super Key) : 각 행을 유일하게 식별할 수 있는 하나 또는 그 이상의 속성들의 집합
- 유일성을 만족해야 함
- 후보키(Candidate Key) : 각 행을 유일하게 식별할 수 있는 최소한의 속성들의 집합
- 속성하나, 하나의 column이 슈퍼키역할을 해야 함
- 유일성 + 최소성
- 기본키(Primary Key)
- 후보키들 중에서 하나를 선택한 키로 최소성과 유일성을 만족하는 속성
- NOT NULL , UNIQUE 제약
- 대체키(Alternate Key)
- 후보키가 두개 이상일 경우 그 중에서 어느 하나를 기본키로 지정하고 남은 후보키들을 대체키라 함
- 외래키(Foreign Key)
- 다른 테이블의 데이터를 참조할 때 없는 값을 참조할 수 없도록 제약
- 참조될 테이블의 속성은 참조될 테이블에서는 기본키(Primary Key)로 설정되어 있어야 함
옵티마이저
- 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성해주는 실행 계획
- 규칙 기반 옵티마이저 / 비용 기반 옵티마이저
- 오라클10 이후 최근에는 비용 기반 옵티마이저 사용
| 우선순위 | 설명 |
|---|---|
| 1 | ROWID를 사용한 단일 행인 경우 |
| 2 | 클러스터 조인에 의한 단일 행인 경우 |
| 3 | 유일하거나 기본키를 가진 해시 클러스터 키에 의한 단일 행인 경우 |
| 4 | 유일하거나 기본키에 의한 단일 행인 경우 |
| 5 | 클러스터 조인인 경우 |
| 6 | 해시 클러스터 조인인 경우 |
| 7 | 인덱스 클러스터 키인 경우 |
| 8 | 복합 칼럼 인덱스인 경우 |
| 9 | 단일 칼럼 인덱스인 경우 |
| 10 | 인덱스가 구성된 칼럼에서 제한된 범위를 검색하는 경우 |
| 11 | 인덱스가 구성된 칼럼에서 무제한 범위를 검색하는 경우 |
| 12 | 정렬 - 병합(Sort Merge) 조인인 경우 |
| 13 | 인덱스가 구성된 칼럼에서 MAX 혹은 MIN을 구하는 경우 |
| 14 | 인덱스가 구성된 칼럼에서 ORDER BY를 실행하는 경우 |
| 15 | 전체 테이블을 스캔(FULL TABLE SCAN)하는 경우 |
인덱스
- 검색 속도를 높이기 위해 사용하는 하나의 기술
- 인덱스의 장점
- 키값을 기로초 하여 테이블에서 검색과 정렬 속도를 향상
- 질의나 보고서에서 그룹화 작업의 속도를 향상
- 테이블행의 고유성을 강화할 수 있음
- 여러 필드로 이루어진 인덱스를 사용하면 첫 필드 값이 같은 레코드도 구분할 수 있음
- 인덱스의 단점
- .mdb 파일 크기가 늘어남
- 여러 사용자 응용 프로그램에서의 여러 사용자가 한 페이지를 동시에 수정할 수 있는 병행성이 줄어듦
- 인덱스 된 필드에서 데이터를 업데이트하거나, 레코드를 추가 또는 삭제할 때 성능이 떨어짐
- 인덱스가 데이터베이스 공간을 차지해 추가적인 공간이 필요해짐
- 인덱스를 생성하는데 시간이 많이 소요될 수 있음
N414 : Note 04 : DB API
🏆ㅤ 학습 목표
🌱 Level 1 : Lecture Note 에 있는 주요 개념을 정의할 수 있으며 예제 코드를 이해하고 재현할 수 있다.
- DB API를 사용하는 이유에 대해서 설명할 수 있다.
- 로컬과 클라우드 데이터베이스를 분류하여 설명할 수 있다.
- 클라우드 데이터베이스를 생성하고 DBeaver를 통해 연결할 수 있다.
- Python DB API의 객체와 메서드를 설명할 수 있으며, 노트 예제인 sqlite3 활용을 재현할 수 있다.
🔝 Level 2 : 예제 코드를 해석하고 응용할 수 있으며 과제를 수행할 수 있다.
- sqlite3를 통해 SQLite을 다룰 수 있다.
- 여러 형태의 자료구조를 가진 데이터를 데이터베이스에 적재할 수 있다.
🔥 Level 3 : Lecture Note 에 있는 주요 개념과 코드를 연결하여 설명할 수 있으며 도전 과제를 수행할 수 있다.
- 클라우드 데이터베이스를 생성하고 DB API를 활용하여 데이터베이스와 소통할 수 있다.
- psycopg2를 통해 PostgreSQL을 다룰 수 있다.
- DB API를 활용하여 주어진 스키마에 따라 테이블을 생성하고, csv 형태의 데이터를 적재할 수 있다.
🚀 Level 4 : Lecture Note 에 있는 개념 중 자신이 모르는 것을 구분해 낼 수 있으며 스스로 목표를 세우고 추가 학습을 진행할 수 있다.
- Pandas를 사용하지 않고 csv 데이터를 다룰 수 있다.
- 파일형, 서버형, 인메모리형 데이터베이스를 구별하여 설명할 수 있다.
- 데이터베이스의 인덱스와 B-Tree 자료구조를 이해하고 연관지어 설명할 수 있다.
오늘의 키워드
- DB API, SQLite, postgreSQL
공부한 내용
PEP 249
- 파이썬에서 명시하는 DB API v2.0 에 대한 문서
SQLite
- 파이썬과 함께 설치되는 가벼운 파일형 관계형 데이터베이스
- sqlite3 모듈로 파이썬에서 사용할 수 있음
import sqlite3
conn = sqlite3.connect('test.db')
# 파일을 생성하지 않고 메모리에서 작업이 가능함
conn = sqlite3.connect(':memory:')
postgreSQL
- psycopg2 모듈로 파이썬에서 사용할 수 있음
import psycopg2 conn = psycopg2.connect( host ="satao.db.elephantsql.com", database ="{데이터베이스 이름}", user ="{사용자 이름}", password ="{사용자 암호}") - URI, URN, URL 차이
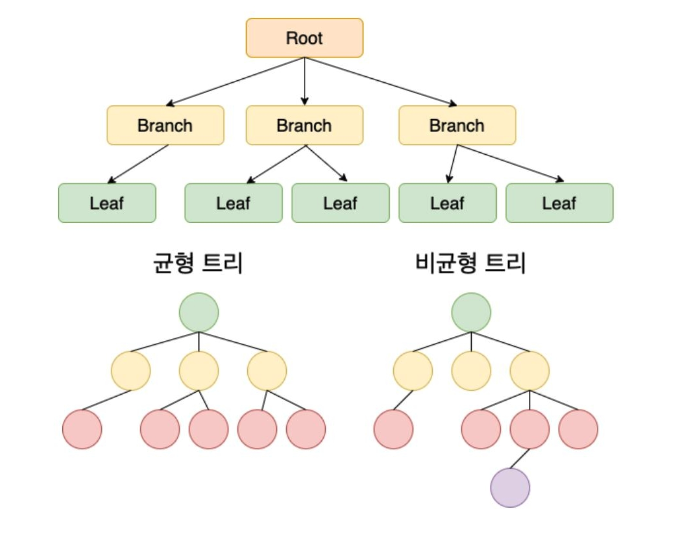
B-Tree
- 인덱스를 위한 대표적인 데이터 구조
Reference
끝까지 읽어주셔서 감사합니다😉
</center>


댓글남기기