
AI 부트캠프 11주 : Deep Learning Applications

코드스테이츠와 함께하는 ‘AI 부트캠프’ 11주차
Deep Learning Applications
주간회고
더 공부가 필요한 부분
다양한 (전이학습)모델의 특징과 차이를 구분해서 모델마다 어떠한 특징이 있는지 이해하고, 다양한 모델을 적용할 수 있도록 코드에 대한 이해가 더 필요할 것 같다.
주간 회고
-
사실(Fact)
딥러닝이 이미지관련 분야에서 어떻게 사용 될 수 있고, 어떻게 모델을 구현할 수 있는지를 학습하였다. -
느낌(Feeling)
사전학습된 모델의 summary를 봐도 모델구조가 쉽게 이해되지 않았다. 과제를 처리하기 위해서 모델을 이해하지 않고 곧바로 모델을 적용해서 제출하면서 ‘이게 되나?’라는 생각이 많이 들었다. -
교훈(Finding)
여러가지 사전학습된 모델의 특징과 구조를 이해하였을 때 모델을 작 적용할 수 있을 것 같다. 요리사가 칼을 잘 알고 있어야 식재료에 알맞는 칼을 선택할 수 있듯이…(물론 식칼로 감자를 깎을 수는 있다!!) -
향후 행동(Future action)
여러가지 모델에 대한 이해를 위한 공부와 여러 모델을 직접 적용하는 두 방법을 병행할 것이다.
N331 : Convolutional Neural Network (CNN)
🏆 학습 목표
Level 1 : Lecture Note 에 있는 주요 개념을 설명할 수 있으며 예제 코드를 이해하고 재현할 수 있습니다.
- CNN(Convolutional Neural Network)의 기본 구조에 대해 설명할 수 있다.
- Convolution & Pooling Layer 의 동작 방식과 조정할 수 있는 값(Stride, Padding 등)에 대해 설명할 수 있다.
- 전이 학습(Transfer Learning)을 설명할 수 있으며 이미지 처리를 위한 대표적인 사전 학습 모델을 2개 이상 설명할 수 있다.
- 직접 CNN 모델을 구축하거나 사전 학습 모델을 사용하여 이미지 분류를 하는 코드를 작성할 수 있습니다.
- 개념과 코딩 Quiz를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 2 : 🔝 Reference 내용을 이해하고, 이를 코드로 작성할 수 있습니다.
- CNN 층이 깊어졌을 때의 장점에 대해 설명할 수 있습니다.
- 이미지 데이터 증강(Image Data Augmentation)의 개념에 대해 이해하고 실제 학습에 적용하는 코드를 작성할 수 있습니다.
- Discussion 에 있는 코딩 과제를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 3 : 🔥 Reference 내용을 설명할 수 있습니다.
- 최근 발표되고 있는 이미지 분류를 위한 사전 학습 모델에는 어떤 것이 있는지 나열하고 각 모델의 특징에 대해 설명할 수 있습니다.
오늘의 키워드
- 합성곱 신경망
- 합성곱(Convolution)
- 풀링(Pooling)
- 완전 연결 신경망(Fully Connected Layer)
- 전이학습
공부한 내용
합성곱 신경망
- 합성곱 신경망(Convolutional Neural Network : CNN)
- 2부분(특징 추출 부분, 분류를 위한 신경망)으로 나뉨

- 특징 추출 부분
- 2부분(Convolution Layer, Pooling Layer)으로 나뉨
- 분류를 위한 신경망
- 2부분(Flatten, Fully Connected Layer)으로 나뉨
- 일반다층신경망과 같음
합성곱(Convolution)
- 이미지의 왼쪽 위부터 합성곱 필터가 슬라이딩하며 계산

- 패딩(Padding)
- Feature map(Output)의 크기를 조절하고, 실제 이미지 값을 충분히 활용하기 위해 사용
- ‘valid’ padding
- out_height = ceil((in_height - filter_height + 1) / stride_height)
- out_width = ceil((in_width - filter_width + 1) / stride_width)
- ‘same’ padding
- out_height = ceil(in_height / stride_height)
- out_width = ceil(in_width / stride_width)
if (in_height % strides[1] == 0): pad_along_height = max(filter_height - stride_height, 0) else: pad_along_height = max(filter_height - (in_height % stride_height), 0) if (in_width % strides[2] == 0): pad_along_width = max(filter_width - stride_width, 0) else: pad_along_width = max(filter_width - (in_width % stride_width), 0)
- 스트라이드(Stride)
- 필터가 슬라이딩할 때 몇 칸씩 이동할지 결정
- Feature map 크기 변화
- $N_{\text{out}} = \bigg[\frac{N_{\text{in}} + 2p - k}{s}\bigg] + 1$
- $N_{\text{in}}$ : 입력되는 이미지의 크기(=피처 수)
- $N_{\text{out}}$ : 출력되는 이미지의 크기(=피처 수)
- $k$ : 합성곱에 사용되는 커널(=필터)의 크기
- $p$ : 합성곱에 적용한 패딩 값
- $s$ : 합성곱에 적용한 스트라이드 값
- $N_{\text{in}}$ : 입력되는 이미지의 크기(=피처 수)
- $N_{\text{out}} = \bigg[\frac{N_{\text{in}} + 2p - k}{s}\bigg] + 1$
- 합성곱 필터가 가중치 역할
- 가중치 개수(파라미터 개수)
- (커널수 3x3) x (input_ch) x (output_ch) + output_bias
풀링(Pooling)
- Pooling Layer
- Max Pooling & Average Pooling
- 가중치가 없고, 채널 수가 변하지 않는 특징
완전 연결 신경망(Fully Connected Layer)
- 다층 퍼셉트론과 같음
- 출력 노드 설정 필요
전이학습
- Transfer Learning(전이 학습)
- 사전 학습 모델(Pre-trained Model)의 가중치를 그대로 가져온 뒤 완전 연결 신경망 부분만 추가로 설계하여 사용
- 사전 학습 모델들
- VGG
- 3x3 필터 사용
- Relu 사용, He 초기화 사용
- Dropout 사용, Adam 사용
- GoogLeNet
- Inception : 세로 방향의 깊이 뿐만 아니라 가로 방향으로도 넓은 신경망 층
- ResNet
- Residual Connection(=Skipped Connection)
- 기울기 소실(Vanishing Gradient) 문제를 어느정도 해결
- VGG
- Data Augmentation
- 일반화(Generalization)가 잘 되는 모델을 만들기 위해서 사용
- 데이터의 양이 적을 때 사용
N332 : Beyond Classification (Segmentation & Object Detection)
🏆 학습 목표
Level 1 : Lecture Note 에 있는 주요 개념을 설명할 수 있으며 예제 코드를 이해하고 재현할 수 있습니다.
- Segmentation의 동작 방식 및 Semantic Segmentation/Instance Segmentation 을 구분하여 설명할 수 있다.
- Transpose Convolution의 필요성과 동작 방식에 대해 설명할 수 있다.
- 기존 모델을 사용하여 U-net 모델을 만든 코드를 이해하고 참고하여 다시 작성할 수 있다.
- Object Detection 의 2가지 방식과 지표에 대해 설명할 수 있다.
- 개념과 코딩 Quiz를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 2 : 🔝 Reference 내용을 이해하고, 이를 코드로 작성할 수 있습니다.
- Objection Detection 모델을 직접 구현한 코드를 보고 이해할 수 있습니다.
- Discussion 에 있는 코딩 과제를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 3 : 🔥 Reference 내용을 설명할 수 있습니다.
- U-net 을 직접 구현한 코드를 보고 이해할 수 있습니다.
- 여러 Object Detection 모델에 대해 알아보고 어떤 방식에 해당되는지 구분할 수 있으며 특정 모델의 적절한 예제를 선택하여 다른 데이터셋에 적용해 볼 수 있습니다.
오늘의 키워드
- segmentation
- FCN
- U-net
공부한 내용
Segmentation
- 분할(Segmentation)
- 하나의 이미지에서 같은 의미를 가지고 있는 부분을 구분하는 것
- 의미적 분할, 개체 분할
- 의미적 분할(Semantic Segmentation)
- 의미적으로 같은 개체에 대해서는 모두 동일하게 라벨링
- 개체 분할(Instance Segmentation)
- 개체를 하나하나 구분하는 것
FCN
- FCN(Fully Convolutional Networks)
- CNN의 분류기 부분, 즉 완전 연결 신경망(Fully Connected Layer) 부분을 합성곱 층(Convolutional Layer)으로 대체한 모델

- 다운 샘플링 Downsampling
- Convolution 과 Pooling 을 사용하여 특징을 추출하는 과정
- 사이즈가 작아짐 (ex. 256x256 → 128x128 → 64x64 …)
- 업샘플링 Upsampling
- 다운샘플링과 반대로 사이즈가 커지는 과정
- Transpose Convolution
U-net
- 다운샘플링, 업샘플링 과정은 FCN과 비슷함
- FCN과 다른점은, Downsampling 출력으로 나왔던 Feature map 을 적당한 크기로 잘라서 붙여준 뒤 Upsampling 과정에서 추가 데이터로 사용

N333 : AutoEncoder (AE)
🏆 학습 목표
Level 1 : Lecture Note 에 있는 주요 개념을 설명할 수 있으며 예제 코드를 이해하고 재현할 수 있습니다.
AutoEncoder(AE)의 형태와 학습 방식을 연관지어 설명할 수 있다. Latent Vector(잠재 벡터)의 개념에 대해 설명할 수 있다. AutoEncoder가 활용되는 Task를 AutoEncoder의 특징과 연관지어 설명할 수 있다. AutoEncoder 예제를 참조하여 간단한 모델을 직접 구현해보고 다른 데이터셋에 적용할 수 있다. 개념과 코딩 Quiz를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 2 : 🔝 Reference 내용을 설명할 수 있습니다.
매니폴드(Manifold)의 개념을 이해하고 매니폴드 학습(Manifold Learning)이 AutoEncoder와 어떤 연관이 있는지 설명할 수 있다.
Level 3 : 🔥 Reference 내용을 설명할 수 있습니다.
VAE(Variational AutoEncoder)의 동작 방식을 이해하고 일반적인 AutoEncoder 와의 차이점에 대해서도 이해할 수 있습니다.
오늘의 키워드
- 오토인코더
- 잠재 벡터
공부한 내용
오토인코더

- Encode 부분
- 차원 축소
- Decoder 부분
- 원래의 크기로 복귀
N334 : Generative Adversarial Network (GAN)
🏆 학습 목표
Level 1 : Lecture Note 에 있는 주요 개념을 설명할 수 있으며 예제 코드를 이해하고 재현할 수 있습니다.
- GAN의 학습 방식과 생성자(Generator)와 판별자(Discriminator)에 대해서 설명할 수 있다.
- CycleGAN 이 동작하는 방식에 대해 설명할 수 있다.
- 개념과 코딩 Quiz를 통해서 위 학습 목표를 달성하였는지 점검해 볼 수 있습니다.
Level 2 : 🔝 Reference 내용을 설명할 수 있습니다.
- CycleGAN의 코드를 설명할 수 있다.
Level 3 : 🔥 Reference 내용을 설명할 수 있습니다.
- 여러 가지 GAN 모델에 대해서 알아보고 그 중 StyleGAN의 컨셉과 코드를 설명할 수 있다.
오늘의 키워드
- GAN, 생성자, 판별자, loss
공부한 내용
GAN
- 생성적 적대 신경망 Generative Adversarial Networks
- 생성자(Generator)와 판별자(Discriminator)의 손실을 최소화하는 생성 모델
생성자
- Random Noise에서 시작
- Transpose Convolution으로 Upsampling하여 이미지 생성
- 원하는 이미지 사이즈(예: 28X28)가 나오도록 Conv2DTranspose를 겹겹이 쌓음
- 은닉층의 활성화 함수는 ReLU 함수의 변형인 LeakyReLU 함수를 사용
- LeakyReLU 는 음수에서 0으로 수렴하지 않는 장점이 있음
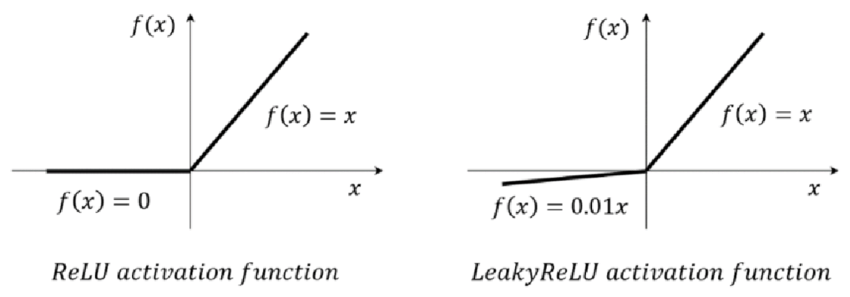
- 활성화 함수 이전에 배치 정규화(Batch Normalization)을 적용
판별자
- 활성화 함수 = LeakyReLU
- 드롭아웃(Dropout)을 적용


댓글남기기